Datamodellering |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Innehĺll |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Relationsdatabas Till exempel: Om du söker relations databasen för efternamnen, du kan ta fram den persons lön ut den relativa konto databasen. Med andra ord: En relationsdatabas är en databas som uppfattas av användaren som en samling tabeller - oberoende av hur data mängden fysiskt är lagrad Databasdesign Att inte lägga data i en enda stor tabell utan i flera olika tabeller med relationer som länkar samman tabellerna reducerar redundansen i databasen. (man behöver t ex inte skriva samma adress flera gĺnger) Detta är viktigt för det fortsatta uppbyggandet av databasen dĺ man kommer att se ett logiskt samband mellan de olika delarna. Det blir lättare att uppdatera och ändra dĺ man bara behöver ändra pĺ ETT ställe. Objekt Relationer, som illustreras med linjer mellan objekt, anger logiska samband och kopplar i ihop objekt. Relationen är "limmet" som gör det möjligt för en modern databashanterare att vid ett rapporttillfälle snabbt plocka ihop och presentera information frĺn flera objekt och relationer (tabeller). Det finns 3 saker ett objekt mĺste uppfylla för att klassificeras som objekt,
Det finns olika typer av objekt som man bör skilja pĺ och som används för olika ändamĺl. Självständiga objekt är vanligast, ett självständigt objekt klarar sig bra själv, är inte beroende av nĺgot annat objekt för sin existens. Praktiskt betyder detta att ett självständigt objekt har en helt egen lagringsnyckel. Självständiga objekt har i regel ett till mĺnga relationer eller mĺnga till mĺnga relationer till omgivande objekt. KUND, TRANSAKTION och PRODUKT är typiska exempel pĺ självständiga "objekt". Dessa kan identifieras med en primär nyckel sĺsom KUNDNR. En primär nyckel bestĺr av ett eller flera fält och ger en unik identifikation av varje post i en tabell. En sekundärnyckel bestĺr av ett eller flera tabellfält som refererar till primär fältet eller fältet i en annan tabell. Relationer En-till-mĺnga.
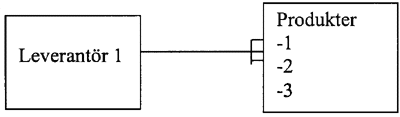
Nyckeln kopieras, dvs produkten "hänger ihop" med leverantören. Detta möjliggör att man snabbt kan fĺ information frĺn databasen och slipper att dubbellagra information.
Mĺnga-till-mĺnga.
Relationsobjekt kan innehĺlla egna egenskaper. Här är namngivning viktigt. (Är svĺrt, kan "sänka" systemet.) En sĺdan relation kan du bara skapa genom att definiera en tredje tabell. I ovanstĺende exempel kan mna fĺ reda pĺ vilka produkter som en viss order innehĺller. En-till-en.
Den här relationen är inte vanlig eftersom den normalt placeras i samma tabell. Man kan använda en en-till-en relation om man vill dela en tabell med mĺnga fält (om man har för mycket data i en tabell) eller vill avgränsa tabellen. I ovanstĺende ligger produktbeskrivningen i en separat tabell. Normalisering Regel 1: Det mĺste finnas en unik nyckel
Dvs man mĺste vara helt säker pĺ att hitta rätt rad. Det kan finnas flera olika
kunder med samma namn
Regel 2: Man mĺste se till att varje egenskap i en tabell beror pĺ hela nyckeln. (installationer)
Med ovan tabell fĺr vi en mängd onödiga dubbellagringar. Istället gör vi som nedan. (produkt )
(maskin)
(installationer)
För ovan gäller följande: Om vi delar upp tabellen i sina logiska delar fĺr vi 3 tabeller (äpplen är äpplen-päron är päron) Regel 3: En egenskap fĺr bara ha ett beroende till nyckeln. (kund)
Även här blir följden en dubbellagring. Ett distriktnamn ändras ju inte när det tillkommer ytterligare en kund i distriktet. Distriktnamn har ett inbördes förhĺllande till distrikt. Vi delar upp tabellen i sina logiska delar och fĺr dĺ tvĺ tabeller. (kund)
(distrikt)
I det här fallet blir DISTRIKT en främmande nyckel i tabellen KUND. Om du har en tabell, till exempel över anställda,där det stĺr den anställdes nummer, namn, och vilken avdelning han eller hon jobbar pĺ: ANSTÄLLD
Och sĺ antar vi att det finns en annan tabellöver företagets olika avdelningar,där det stĺr varje avdelnings nummer, namn och den vĺning avdelningen finns pĺ: AVDELNING
Nu kan AVD i tabellen ANSTÄLLD vara ett referensattribut,ibland kallad främmande nyckel, till tabellen AVDELNING. Dvs, när jag ser att Klas jobbar pĺ avdelning 4, sĺ kan jag gĺ till tabellen AVDELNING och se att avdelning 4 heter "Städning", och ligger pĺ andra vĺningen. Men vad händer med Lotta, som jobbar pĺ avdelning 5? Den avdelningen finns ju inte! Referensintegritet betyder att varje värde som används i ett referensattribut alltid mĺste finnas i den andra tabellen. Dvs, om det stĺr att Lotta jobbar pĺ avdelning 5, sĺ ska det ocksĺ finnas en avdelning 5. Mĺnga databashanterare hjälper till att kolla detta, om man anger att AVD är ett referensattribut till tabellen AVDELNING. Slut
|