 PISIT' S THAI NATURAL LANGUAGE PROCESSING LABORATORY
PISIT' S THAI NATURAL LANGUAGE PROCESSING LABORATORY
This lab is formed since August 26, 1998
e-mail: pisitp@yahoo.com
For C7 members, please check this C7 address list.
KEYWORDS
Thai Natural Language Processing Lab., words
segmentation, dictionaries, algorithms, Thai text-to-speech.
โครงสร้างข้อมูลพจนานุกรมแบบทรัย
(Trie Data Structure)
กล่าวนำ
โครงสร้างข้อมูลแบบทรัยเป็นโครงสร้างข้อมูลที่นิยมใช้สำหรับเก็บพจนานุกรมคำไทย
เพื่อการตัดคำภาษาไทย สืบเนื่องมาจากให้ประสิทธิภาพสูงทั้งในแง่ของความรวดเร็วในการ
ทำงานและความประหยัดเนื้อที่ในการจัดเก็บข้อมูลพจนานุกรม นอกจากนี้ยังนิยมใช้สำหรับ
การทำดัชนีเพื่อการสืบค้นข้อมูลจากข้อความและเอกสารขนาดใหญ่ ทรัยคือโครงสร้างข้อมูล
แบบต้นไม้ที่มีกิ่งก้าน (edges) แทนตัวอักษรที่เข้ารหัสเป็นข้อมูลใด ๆ ที่ต้องการจัดเก็บ [1] ใน
กรณีที่ใช้ทรัยจัดเก็บข้อมูลพจนานุกรม คำหนึ่งคำก็จะได้จากเส้นทาง (Path) จากรากไล่ไปจน
ถึงใบดังตัวอย่างประโยค
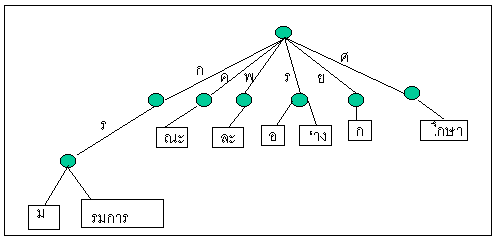
คณะกรรมการกรมพละศึกษารอยกร่าง
ข้อความจากตัวอย่างข้างบนประกอบด้วยคำต่าง ๆ ดังต่อไปนี้ จะสังเกตเห็นว่าไม่มีการ
จัดเก็บอักษรที่มีส่วนต้นซ้ำกันเมื่อทำการจัดเก็บด้วยโครงสร้างข้อมูลแบบทรัย
คำ......ทรัย
กรม.....กรม
กรรมการ.รมการ
คณะ.....คณะ
พละ.....พละ
รอ......รอ
ร่าง....่าง
ยก......ยก
ศึกษา...ึกษา
เมื่อนำไปจัดเก็บในโครงสร้างข้อมูลแบบทรัยจะได้ดังรูปข้างล่าง
การสร้างโครงสร้างข้อมูลทรัย
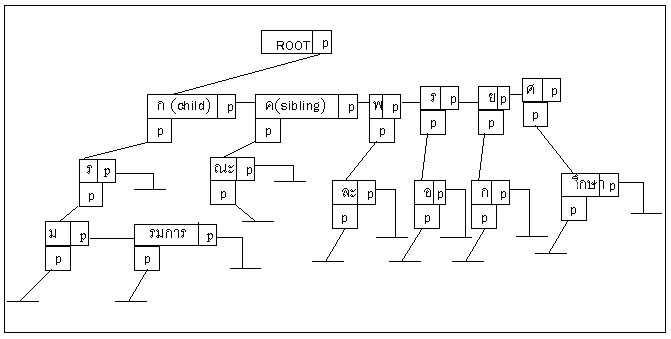
การสร้างโครงสร้างข้อมูลแบบทรัยอาจทำได้คือใช้อะเรย์ (Array) หรือใช้พ้อยเตอร์
(Pointer) ก้ได้ ในที่นี้จะสร้างด้วยการใช้พ้อยเตอร์แบบหลายทางโดยให้โหนดแรกเป็นลูกและ
โหนดถัดไปเป็นลูกในระดับเดียวกัน (First Child Next Sibling Multi way Tree) รูปข้างล่างคือ
การสร้างทรัยแบบพ้อยเตอร์ดังกล่าวของตัวอย่างจากทรัยในรูปข้างบน
เนื่องจากทรัยคือโครงสร้างข้อมูลแบบต้นไม้ดังนั้นความรวดเร็วในการทำงานโดยเฉลี่ย
เป็น O(log n) [2] หรือความเร็วในการทำงาน มีผลแปรผันน้อยมากกับขนาดของข้อมูลจึงมี
ความเหมาะสมกับข้อมูลขนาดใหญ่มากกว่าโครงสร้างข้อมูลแบบเดิมที่ใช้ คือลิงค์ลีสต์ที่แปรผัน
โดยตรงกับขนาดข้อมูลที่ป้อนให้ O(n) ในแต่ละโหนดของทรัยเมื่อใช้พ้อยเตอร์เป็นตัวสร้างจะ
ประกอบไปด้วยสามส่วนคือ ข้อมูล พ้อยเตอร์ชี้ไปยังลูกตัวแรก (first child) และพ้อยเตอร์ชี้ไป
ยังลูกข้างเคียง (next sibling) โหนดของทรัยดังกล่าวนี้สามารถแสดงในลักษณะการนิยามตาม
แบบภาษาซีได้ดังต่อไปนี้
typedef struct trie_node *trie_ptr;
struct trie_node
{
element_type element;
trie_ptr first_child;
trie_ptr next_sibling;
}
ผลการทดลองสร้างทรัย
ได้ทำการทดลองใช้ทรัยเป็นโครงสร้างข้อมูลสำหรับโปรแกรมตัดคำภาษาไทย นำ
โปรแกรมดังกล่าวไปทำการตัดคำกับข้อมูลกฎหมายไทยสองฉบับ ชุดแรกคือพระราชบัญญัติ
กองทุนเพื่อโครงการอาหารกลางวันในโรงเรียนประถมศึกษาพ.ศ. สองห้าสามห้าซึ่งมีขนาด
7,686 ตัวอักษรและชุดที่สองคือชุดแรกรวมกับพระราชบัญญัติวิทยุกระจายเสียงและวิทยุโทร
ทัศน์พ.ศ. สองสี่เก้าแปด ซึ่งมีขนาดรวม 25,846 ตัวอักษร โดยที่กฎหมายทั้งสองได้มาจากแม่
ข่ายใยแมงมุมของคณะกรรมการกฤษฎีกา และได้ทำการทดลองกับพจนานุกรมคำไทยสองชุด
โดยชุดแรกคือพจนานุกรมคำไทยที่มีความถี่ในการใช้งานในชีวิตประจำวันสูงมีขนาด 3,963
คำ และอีกชุดเป็นพจนานุกรมคำไทยทั่วไปซึ่งมีขนาด 17,859 คำ ได้ทำการสรุปผลการทดลอง
ไว้ในตารางข้างล่างนอกจากนี้การทดลองได้พบสถิติของโครงสร้างข้อมูลทรัยที่น่าสนใจเมื่อนำ
ไปจัดเก็บพจนานุกรมภาษาไทยคือพบว่าจากพจนานุกรมชุดแรกได้จำนวนโหนดทั้งหมดในทรัย
เป็น 4,751 โหนด มีจำนวนโหนดในระดับที่สอง (ระดับแรกคือราก) เป็น 42 โหนด มีค่าเฉลี่ย
ของโหนดในระดับที่สามเป็น 17 และค่าเฉลี่ยของโหนดในระดับใบ (leaf) เป็น 5 ในขณะที่จาก
พจนานุกรมชุดที่สองพบว่าได้จำนวนโหนดทั้งหมดในทรัยเป็น 18,952 โหนด มีจำนวนโหนด
ในระดับที่สอง (ระดับแรกคือราก) เป็น 48 โหนด มีค่าเฉลี่ยของโหนดในระดับที่สามเป็น 21
และค่าเฉลี่ยของโหนดในระดับใบ (leaf) เป็น 17 จะเห็นได้ว่าค่าจำนวนโหนดเฉลี่ยในแต่ละ
ระดับมีค่าใกล้เคียงกันถึงแม้จำนวนคำในพจนานุกรมต่างกันมากซึ่งเป็นเหตุผลที่ทำให้ความเร็ว
ในการทำงานค่อนข้างคงที่เมื่อใช้โครงสร้างข้อมูลแบบทรัยนี้เป็นโครงสร้างข้อมูลสำหรับ
พจนานุกรม
พิจารณาตารางผลการทดลองข้างล่างเมื่อเพิ่มขนาดพจนานุกรมจาก 3,963 คำเป็น
17,859 คำ หรือเพิ่มขึ้น 350% พบว่าเมื่อใช้โครงสร้างข้อมูลแบบทรัยเวลาที่ใช้ในการตัดคำ
เพิ่มขึ้น 48% ที่ขนาดข้อมูล 7,686 ตัวอักษร แต่ที่ขนาดข้อมูล 25,846 ตัวอักษร เวลาที่ใช้
งานเพิ่มขึ้น 12% เปรียบเทียบกับโครงสร้างข้อมูลแบบเดิมเวลาเพิ่มขึ้น 374% ที่ขนาดข้อมูล
3963 คำ และเพิ่มขึ้น 383% ที่ขนาดข้อมูล 25,846 ตัวอักษร
จากตารางเดียวกันพบว่าเมื่อเพิ่มขนาดข้อมูลจาก 7,686 ตัวอักษรเป็น 25,846 ตัว
อักษร หรือเพิ่มขึ้น 236% พบว่าความเร็วของทรัยเพิ่มขึ้น 214% และ 137% ที่ขนาด
พจนานุกรมจำนวน 3,963 คำ และ 17859 คำ ตามลำดับ เปรียบเทียบกับโครงสร้างข้อมูล
แบบเดิมใช้เวลาในการทำงานเพิ่มขึ้นเป็น 232% และ 238% ที่ขนาดพจนานุกรม จำนวน
3,963 คำ และ 17859 คำ ตามลำดับ
เอกสารขนาด 7,686 อักษร..โครงสร้างข้อมูลแบบเดิม........ทรัย
พจนานุกรมขนาด 3,963 คำ............19 วินาที......1.59 วินาที
พจนานุกรมขนาด 17,859 คำ...........90 วินาที.....2.36 วินาที
เอกสารขนาด 25,846 อักษร..โครงสร้างข้อมูลแบบเดิม.......ทรัย
พจนานุกรมขนาด 3,963 คำ............63 วินาที.....5.00 วินาที
พจนานุกรมขนาด 17,859 คำ..........304 วินาที.....5.59 วินาที
สรุป
จากการทดลองใช้โครงสร้างข้อมูลแบบทรัยนี้สร้างพจนานุกรมเพื่อการตัดคำภาษาไทย
พบว่าสามารถทำงานได้รวดเร็วกว่าโครงสร้างข้อมูลแบบเดิมคือลิงค์ลีสต์แบบเรียงลำดับเป็นอัน
มาก โดยที่ความเร็วในการทำงานค่อนข้างจะคงที่ถึงแม้เอกสารจะมีขนาดต่างกัน หรือถึงแม้เพิ่ม
จำนวนคำในพจนานุกรมขึ้นอีกเป็นจำนวนมาก ความเร็วในการทำงานก็ยังคงที่อยู่ ในขณะที่
โครงสร้างข้อมูลแบบเดิมจะมีความเร็วในการทำงานที่แปรผันกับจำนวนคำในพจนานุกรมและ
ขนาดของเอกสารเป็นอันมากทั้งนี้เนื่องจากความเร็วของการทำงานของโครงสร้างข้อมูลแบบท
รัยจะขึ้นอยู่กับความยาวของคำในพจนานุกรมแต่แปรผันกับจำนวนคำและขนาดข้อมูลน้อยมาก
เอกสารอ้างอิง
[1] Witoon Kanlayanawat, Somchai Prasitjutrakul, "Autometic Indexing for Thai Text
with Unknown Words using Trie Structure" ,
Dept. of Computer Engineering, Chulalongkorn University, NCSEC98 conference,
Kasetsart University, 1998
[2] Mark Allen Weiss, "Data Structures and Algorithm Analysis in C", Florida
International University,
The Benjamin/Cummings Publishing Co., ltd., 1992