
Reprinted from COMPUTERS AND BIOMEDICAL RESEARCH, Vol. 2, No. 5, October 1969
Copyright (c) 1969 Academic Press,Inc.
Special Thanks to Ana Merced of Harcourt Brace & Company for all her assistance.
The original document is a 1969 paper. The OCR process may have introduced errors. Other than a spell check, the contents of the original document has not been changed, although the document has been formatted.
Design and Implementation of a Clinical Data Management System *
R.A.GREENES, A.N. PAPPALARDO, C.W. MARBLE, AND
G. OCTO BARNETT
Laboratory of Computer Science,
Massachusetts General Hospital,
Department of Medicine,
Harvard Medical School,
Boston,
Massachusetts 02114
Received March 10, 1969
Increasing activity in the use of computers for acquisition, storage, and retrieval of medical information has been stimulated by the growing complexity of medical care, and the needs for standardization, quality control, and retrievability of clinical data. Criteria for the design of a clinical data management system include flexibility in its interface with its environment, the capability of handling variable length text string data, and of organizing it in tree-structured files, the availability of this data to a multi-user environment, and the existence of a high-level language facility for programming and development of the system. The scale and cost of the computer configuration required to meet these demands must nevertheless permit gradual expansion, modularity, and usually duplication of hardware. The MGH Utility Multi-Programming System (MUMPS) is a compact time-sharing system on a medium-scale computer dedicated to clinical data management applications. A novel system design based on a reentrant high-level language interpreter has permitted the implementation of a highly responsive, flexible system, both for research and development and for economical, reliable service operation.
INTRODUCTION
For a number of years, the Concept of a computer-based medical record has generated considerable interest. As the process of delivery of medical care becomes more complex and involves more professional and nonprofessional personnel, the medical record will need to assume a central role in achieving the continuity and comprehensiveness that is essential. The medical record further provides the primary means by which quality control, auditing of the medical care process, and research into the diagnosis and treatment of disease can be achieved. Despite changing functions and increased demands on it, the medical record has, nevertheless, changed little in form over the past century. Medical records possess no organization by diagnostic or therapeutic problem; notes relevant to a particular aspect of a patient's health may be obtained only by leafing through an entire volume. Terminology is not standard, data is not organized in well defined formats, and notes are often illegible. As a consequence, the objective of using the computer for the acquisition, storage, and retrieval of medical record information is gaining increasing impetus.
The next section will define criteria which the authors have found to be important in the design of systems for clinical data management, and the subsequent section will describe a novel system which has been implemented to meet these requirements. The system to be described has been in operation for over a year. The extent to which it has fulfilled its design expectations has led the authors to believe that the criteria defined have general applicability, and that the system implemented has considerable utility for clinical data management.
In the following discussion, it should be noted that the term "data management system" should not be confused with another term, "management information system", which appears frequently in the business computing literature. The function of a clinical data management system, as we use the term, is to support on-line input, inquiry, or retrieval of information from a central data base, maintained by the computer system, through a variety of access points.
DESIGN CRITERIA FOR A CLINICAL DATA MANAGEMENT SYSTEM
The internal design of an information system dictates constraints on the external attributes of such a system. The characteristics that must be resolved include the number, priority, and level of responsiveness of the users, both active and inactive; the ratios among CPU time, connect time, and input/output time; the structure, magnitude, and timeliness of file information; the profile of application programs in regard to size, type, and interactiveness; user requirements for development and service modes of operation; and finally the overall economic justification. It is important to recognize that flexibility is important in the developmental process, but that a planned evolution to a service system limits the inclusion of various general purpose features in a system.
1. INTERFACE REQUIREMENTS
Clinical information about a patient derives from a variety of sources--the patient, the attending physician, consultants, the radiologist, the clinical laboratory, etc. The problems of using the computer to obtain information from each of these sources have begun to receive attention. Perhaps the most widespread activity of this type has been the development of systems for clinical laboratory information processing. This is one of the well defined tasks in the hospital in which information handling has long been a recognized bottleneck. Laboratory data may be obtained directly from instrumentation or by clerical entry of numerical or simple text information. A number of these systems are under development or functioning in various institutions.1,2,3,4
With the exception of laboratory data, much of the clinical information in the medical record is generally recorded in narrative or free text form. The problems of dealing with these kinds of data are more complex. Most investigators are convinced that natural language is not a form suitable for computer record keeping applications, except perhaps in circumscribed areas with limited vocabulary and syntax.5,6 As a result, there is a significant amount of work currently being devoted to the development of methods for structuring this narrative data; 7,8,9 it is generally recognized that new ways of capturing such information need to be introduced A variety of means may be used to impose structure on clinical data, e.g., entry of data by the use of check lists, forms, or direct user-computer dialogue. Interactive dialogues for the capture of narrative data are usually based on hierarchical organization and presentation to the user of the subject material. Any particular topic may then be pursued to an arbitrary depth, by means of a succession of increasingly discriminating selections by the user from the options presented. A variety of programs for interactive acquisition of clinical data have been developed, and have generated needs for special terminals, display formats, and conversation languages. As an example, conversational programs have been devised for the on-line acquisition of a patient's medical history.10,11 Other systems aimed primarily at the physician, have been designed for the purpose of entry of physical examination notes,12 the recording of progress notes, or the generation of x-ray reports by the radiologist.13,14 In all such cases, special attention needs to be given to the interface (hardware, software, and environmental) of the system with the individuals who have to use it.
As the potential of clinical data management systems are recognized, the systems will need to posses the capability to meet a diversity of output needs--the display of reports or summaries, organized topically or chronologically, the production of tables and graphs, etc. Information obtained by dialogue must often be translated into more precise medical terminology, or compacted into coded representation. Flexibility in storage, retrieval, and output of information is essential.
2. VARIABLE LENGTH TEXT HANDLING CAPABILITIES
The complexity and variety of data that must be handled in a clinical information system impose a number of requirements on the system. A considerable amount of the information that is input is in the form of text strings of variable length. The processing of input often requires syntax checking or limit checking. String comparisons, extractions, and concatenations need to be performed. When special driver languages or monitor subsystems are employed to control dialogues between the user and the computer, string processing capabilities are mandatory. Most existing higher level languages do not provide the need combination of algebraic and boolean expression handling capabilities with the ability to handle string information.
3. HIERARCHICAL DATA BASE ORGANIZATION
The efforts to develop specialized clinical data management applications such as those referenced above are still relatively primitive. There have been very few concerted efforts devoted to the general problem of management of medical record data, the development of integrated patient data files, and the implementation of systems for long-term storage and retrieval of this data.15,16 Among the difficulties faced by the few development efforts that have been undertaken have been the lack of generality in their approaches, and the reliance on highly specific programming languages, file structures, and file handling routines.
A most important requirement of systems for clinical data management is the ability to handle the several levels of structure of a medical record data base, and to support the rather complex updating and retrieval needs of such a system. An example of a typical patient data file, such as exists in the information system under development at the Massachusetts General Hospital, is illustrated in Fig. 1. This indicates the typically hierarchical (tree-like) structure of the data base;
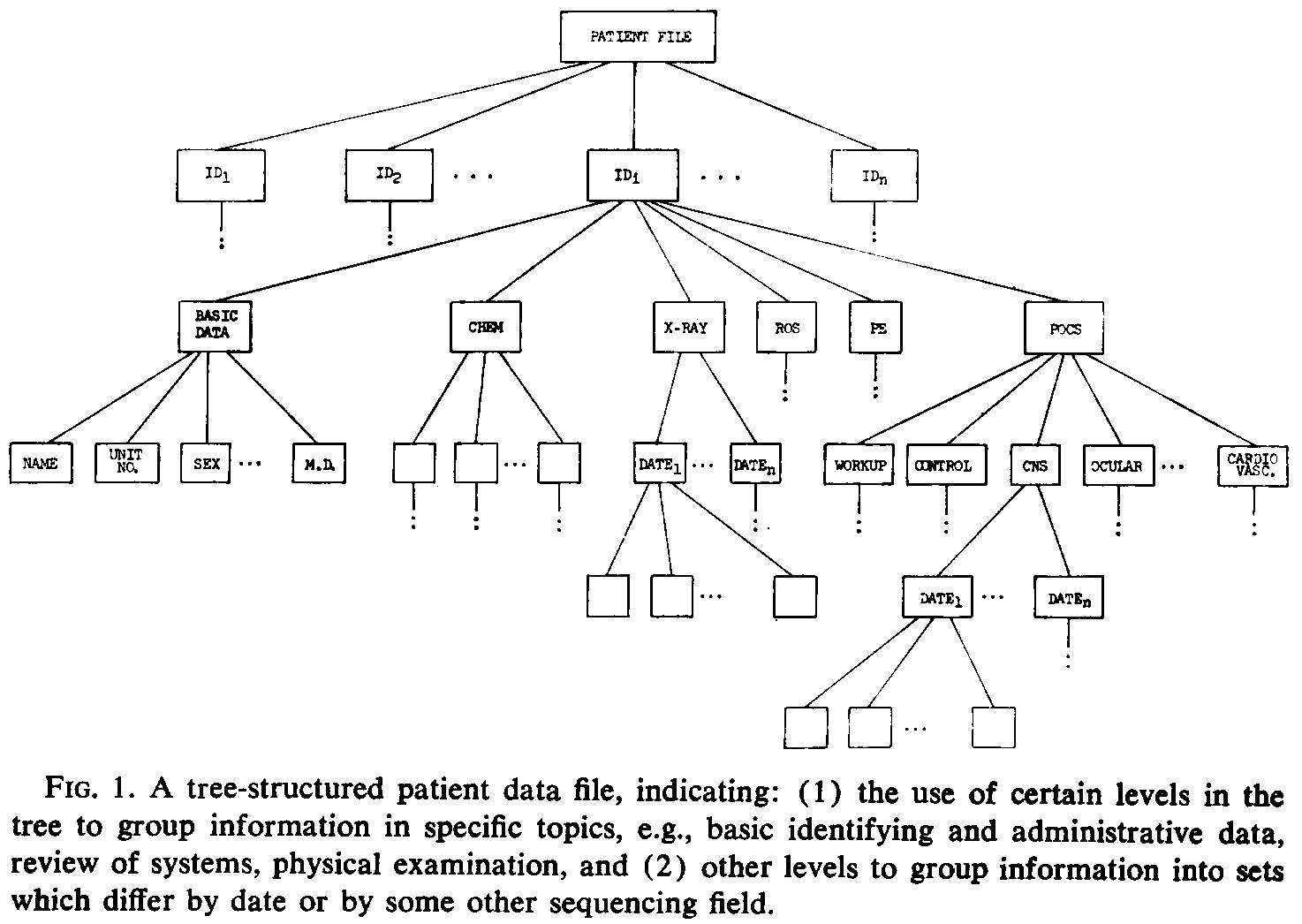
which has both a topical and chronological organization. Most computer systems currently available do not have the ability to handle hierarchical files flexibly, although this is one of the most needed capabilities for clinical data management.
4. MULTI-USER ACCESS TO CENTRAL DATA BASE
A further requirement of a clinical data management system is that the information stored be accessible to a variety of users concurrently. Access to a particular patient's record may be at a high frequency for a critically ill in-patient or at a relatively low frequency for an ambulatory care patient. However, this access may be from a variety of terminals, by a variety of programs in the information system. Among the possible purposes for accessing a file might be to report a laboratory result, to enter an x-ray impression, to record a progress note, or to answer a specific inquiry. Many of these activities occur independently but must share a common data base. Since they may occur simultaneously, time-shared usage of the system is essential. Nevertheless, manipulation of the data base must occur without time-sharing conflict. A conflict might occur if two users were to update a portion of the data base simultaneously, which, without special provision. might result in loss of information.
5. LARGE STORAGE CAPACITY
The conversational environment in which such systems are designed to operate typically demands little computer processing power. When data is entered, the system must check on its legality, decide where to file it, and select the appropriate response to the user. None of these actions requires large amounts of processing. Generation of reports may involve manipulation of information on peripheral storage to assemble the data needed, but only a small amount of processing to actually format and produce the report. Large volumes of data need to be available for low level, low frequency usage. Thus, one does not need computing power as much as the availability of peripheral storage with large capacity. Most of this data may be potentially accessed at any time, and therefore should be on a random-access device such as a disk, drum, or data cell. There should be hierarchies of peripheral storage, since access time for data that is required only rarely need not be as rapid as for that which is utilized more frequently.
6. LOW CENTRAL PROCESSOR USAGE
In a conversational data management system, programs spend much of their time being input-output hung, i.e., doing disk activity or completing a transaction at a terminal. Here again, there is not a large demand for the central processor. In contrast to most numerical applications where central processing power is the limiting factor, in a conversational environment the time necessary to complete a task is often limited by the speed of the input/output equipment or the human response time at a terminal. As a consequence of the small demand for the central processor, one can theoretically time share a large number of user. Efficiency of use of the central processor is determined by how rapidly the time-sharing monitor can change from one user to another. This swapping overhead is the delay before a particular user program can run after a previous user has quit the run state, due to an input/output hang, expiration of time slice, or termination of its task. When the central processor is not being fully utilized, swapping overhead tends to determine response time of the system.
7. HIGH-LEVEL LANGUAGE
One of the most time-consuming aspects of developing information system programs involves the optimal interfacing of the system with its users in a particular application area. This requires much attention to human engineering, and much modification and revision of programs. A number of systems for clinical data management have been implemented on relatively small computers. This has usually been necessary because development was a gradual process and started with limited objectives. Since high-level languages have not generally been available on small machines, most programming has been done in machine language. The expense and inefficiency of writing, debugging, and modifying such programs have been serious obstacles to active research and development. A few clinical data management systems have used large general purpose computers which could provide much increased flexibility (although still not enough from the point of view of certain requirements we have outlined). However, in view of the rather small amount of central processing which occurs, the overhead of a large operating system on a major computer has often seemed excessive. Furthermore, because of the reliability requirements of a clinical data management system, modularity and duplication of hardware is desirable and often essential. Because of the multiplied expense entailed by hardware redundancy, this is typically feasible only with inexpensive, minimal configurations.
THE MGH UTILITY MULTI-PROGRAMMING SYSTEM (MUMPS)
We have found that a most satisfactory way of meeting a number of the objectives and requirements detailed above has been through the design and use of a special purpose time-sharing system implemented on a computer dedicated to data management applications.
1. THE TIME-SHARING SYSTEM
The MGH Utility Multi-Programming System (MUMPS) is a compact timesharing system on a medium scale computer. It is currently implemented on a PDP-9 (Digital Equipment Corporation) with 24,000 words of 18 bit memory and a Burroughs fixed head disk with three million character storage capacity. A set of terminal scanners are used to interface to remote devices: teletypes, buffered display scopes, line printers, card readers, and A/D converters. Both memory size and peripheral storage capacity can be expanded in the system. However, a single-user version of the system can run on a computer with as little as 8,000 words of memory. In the current version, 16 user may run simultaneously. All active users are assigned partitions of core memory (Fig. 2).
Activating a program consists of finding an available partition and bringing the program into it from the disk; as long as it remains active, it occupies its partition. The use of a partitioned memory system has been dictated by the overwhelming concern for response time. As a result of partitioning, the time-sharing monitor can switch between users in minimum time without having to resort to swapping a program in from a drum or disk. In addition, the monitor automatically overlays external program segments invoked by an active program. Proper linkages are set up to return automatically to the invoking program when execution of the segment terminates.
2. THE INTERPRETER
All application programs in this system are written in a high level interpretive language, a distant ancestor of which is JOSS,17 developed at the Rand Corporation in 1964. It has also been influenced by related languages such as TELCOMP and STRINGCOMP (developed by Bolt, Beranek and Newman, Inc.) and FILECOMP (specified by Medinet Division of General Electric Corp.). The MUMPS language allows the programmer to write a program, debug it, edit it, run it, and modify it concurrently at an interactive session at a console. The interpreter itself is a part of the executive system and is reentrant. The total space taken up by the time-sharing monitor, the input/output monitor, buffers, and reentrant interpreter is currently about 8,000 words of memory. The timesharing and I/O monitors have been specifically tailored to work efficiently with the interpreter. No attempt has been made to accommodate machine language user programs.
A number of major advantages have resulted from the use of the interpreter as the major component of this system. First, programs written in the interpretive language do not require any compiling or assembling. Error comments during execution are typed out at the user's console and allow quick recovery, modification of the program, and reexecution of it. All debugging and modification is done in the same language as that in which the program was written and can be done entirely from the user terminal. This makes modification especially convenient, particularly in a service environment where the trouble shooting necessary to interface a program with an application area is a time-consuming process. The MUMPS environment allows a programming session to take the form of a conversational dialogue between the programmer and the terminal device, thus minimizing the user's time in programming a problem, the computer's time needed in checking it out, and, most important, the elapsed time required to obtain a final running application program.
Execution speed of an interpretive program doing pure central processing may be degraded by a factor of more than 20 to 1 over corresponding code generated in a compiler or assembly language system. However, few programs do pure central processing in a clinical data management environment. Furthermore, a significant part of the work done by programs in the system involves disk manipulation or text string processing activities; in all assembly or compiler language systems this activity is usually handled by the use of subroutines. Therefore the employment of an interpreter as a means of generating calls to these subroutines rather than compiling the calls themselves requires only a small amount of additional processing overhead.
Actually, rather than noting a degraded performance of the system as a whole, a reentrant interpreter may provide a most economical means of achieving a highly responsive time-shared information system. We find that in the conversational environment in which the system is called upon to operate, response times ( a most sensitive measure of efficiency in a time-sharing system) are always less than a second and usually appear instantaneous. There are several reasons that account for this, all of which are related to efficient use of core storage. First, a typical program written in the interpretive language takes up about 10%-20% of the space taken up by the object code generated for a similar program written in a compiler language. Also, dynamic allocation of data and efficient storage of variable length strings and of sparse arrays are standard features of the interpreter. Thus data also takes up considerably less space in this kind of environment. In addition, since the interpreter is reentrant, all programs may share the same utility routines and operating system capabilities. This contrasts rather sharply with conventional compiler or assembly language operating systems, in which each running program must have its own copy of the necessary system routines that it will utilize.
The significant advantage that results from the above features is that programs take up much less space; therefore, a partitioned memory system on a medium or small scale computer becomes feasible. Active programs are typically highly interactive, and are therefore doing only small amounts of processing between input/output requests. Therefore the time sharing monitor is invoked frequently to pass control from one user to another, in order to utilize the central processor as much as possible. In a partitioned system, swapping of the users is very rapid. In systems that use various schemes for submerging disk or drum swapping, users that are running in a conversational mode often do not stay in the run state long enough to submerge the concurrent swapping process. Therefore potential CPU time is unavailable; this unused time may be on the order of 20-50% of the total amount available. The speed that results from not using disk or drum swapping appears, in our experience, to more than offset the overhead of interpretation, with greatly increased efficiency in the utilization of space.
3. THE LANGUAGE.
The most significant advantage of the MUMPS language, however, is the large repertoire of capabilities that it brings to the application programmer. The basic orientation of the language is procedural, much as FORTRAN and ALGOL.
The largest unit of a program is a group of statements called a "part", indicated by an integer part number. A single line or statement in the program is a "step"; it is identified by a step number, consisting of a decimal fraction appended to the part number. Multiple commands may be entered in a single step and are executed one after another. A conditional statement which when evaluated has a false value will, however, cause the rest of the commands in that step to be ignored. Commands may be stated in a long mnemonic form, or for the experienced user, in a much more compact form in which only the first letter of the command is used. A statement preceded by a step number is considered to be in "indirect" or "program" mode, and is stored to be executed as part of a program. A statement without a step number is in "direct" mode, which indicates that it is to be executed immediately after it is entered from the user terminal.
In addition to standard algebraic and boolean processing capabilities, the MUMPS language has a number of operators and functions for handling string or text information. A program can perform string extractions, locations, comparisons, and checking of syntax and form of information. These features are illustrated in Figs. 3 and 4. Figure 3 shows a portion of a program written in MUMPS to read a hospital unit number from a teletype (i.e., entered by a user), to check its syntax, and to reject any improperly formatted responses. Figure 4 shows statements in a program for the clinical chemistry laboratory, permitting entry of a test name and its result. Checks are made on the legality of the test name and reasonableness of the result. Some of the interactive editing capabilities of the language are shown in the figure.
A convenience of the language is its input/output scheme, which permits programs to be written independently of the particular device for which one is programming. One may use any device for which the hardware system has been appropriately interfaced, by merely assigning a device number to a special purpose system variable indicating the device to be utilized. This makes it possible to generate a report on a display scope, for example, and then to use the same program to type it out on a typewriter merely by changing, during execution, the value of the device number assigned to the input/output variable. Formatting and control of position on a page are made very simple by utilization of special format characters and variables indicating current position and line spacing.
4. THE DATA MANAGEMENT FACILITY
The MUMPS language allows local data utilized by a program to be referenced symbolically and space for it to be allocated as needed. Local data is that set of variables established within the domain of a particular program, and available and defined only within that program. The data actually resides within the user partition, and functions as scratch or transient data. Local arrays are treated as if they are intended to be sparse, and only subscripts for which data are defined are allocated space. A symbolic variable used in a program may be given either a numerical value or a variable length string value. When it has a string value, only that space required by the string is actually allocated. Thus for both strings and sparse arrays, the overhead of a compiler system does not exist, in which typically maximum sizes of arrays and maximum lengths for string variables must be allocated.
This philosophy is extended to the management of data on peripheral storage, e.g., on the random access disk. Elements stored in data files are referenced entirely symbolically; the file name is similar to that of a symbolic local variable name in a program. Fields in the data file are treated as array elements and referenced by means of subscripts; subfields are referenced by appending additional subscripts. Data files on the disk thus comprise an external system of arrays, which provide a common data base available to all programs. The arrays which make up this external system are called global variables, and are identified by global array names. A global name (or file name) consists of the character up arrow () followed by at least one alphabetic character. The form of the subscript portion of an array reference consists of an arbitrary number of numeric expressions separated by commas and enclosed by parentheses.
The structure of these arrays is hierarchical, and any node within the array tree may possess a numeric and/or string data value and/or a pointer to a lower level in the tree. Data may be stored at any level, and there are no constraints to the dimension or the size of the array. In addition, the quantity and magnitude of subscripts for an array are dynamic so that, not only may the content of an array change during usage, but also its structure may vary.
To avoid time-sharing conflicts, a program may prevent other programs from having access to one or more global arrays which it is in the process of altering in some way, by the use of the command OPEN. The argument of OPEN may be one array name or a list of array names. OPEN prevents any other program from altering data in any of the specified arrays. The effect of OPEN is canceled when the program ends or at the occurrence of the command CLOSE, which does not require any arguments, and releases all opened arrays to other users in the system.
Since modification of content and structure of a global array may be caused by a variety of programs in the system, a particular program must sometimes examine the current configuration of an array before attempting to access or update it. MUMPS provides a set of global array functions to determine the type and structure of a global array. These functions permit the programmer to locate the nodes where information is stored within an array, and nodes within the array which are empty and thus available for data storage.
The use of global arrays will be described in some detail because of the significance of a hierarchically organized, symbolically accessed, common data base in a clinical data management system. The storage of data into an array is accomplished solely by the assignment command, SET. Consider the following statement:
SET
Assume the global array name APR is reserved for the active patient record file. Each patient in the file is accessed through his hospital unit number, in this case, a local variable UN. Both NAME and AGE are also local variables whose values indicate the appropriate category at the second level of the array. This statement then assigns the string value "JOHN DOE" and the numeric value 34 to the specific second level categories, name and age respectively. Subsequently, a statement such as:
SET APR(UN,CHEM,N)=$DATE.",".TEST
might define the Nth laboratory test in the Chemistry Lab with the double field entry of the date concatenated by means of the dot operator with a comma and the test name.
Retrieving data from global arrays is no different from retrieving data from local arrays. Both consist of ascertaining the value of a subscripted variable by using it within a numeric or string valued expression. The statement:
TYPE "THE AGE OF ",APR(UN,NAME)," IS "APR(UN,AGE)
will effect the printout:
THE AGE OF JOHN DOE IS 34
To print out a list of a patient's laboratory tests (assuming APR(UN, CHEM) is the total number of tests defined) the following statement might be used:
FOR I=l:l:APR(UN,CHEM) TYPE !,APR(UN,CHEM,I)
The KILL command when applied to a specific node in a global array, prunes the array tree at that node. Any data value and or array pointers to lower level nodes are removed, and that node reverts back to an undefined status. The statement KILL APR(UN) would delete all information for the patient defined by the local variable UN.
Included in the global array syntax is the "naked" global variable. The form of the naked variable consists of the up-arrow followed by a subscript enclosed in parentheses. This notation is equivalent to the last previously used global array reference except that the value of the last subscript is replaced with the value of the subscript in the naked variable. For example, the statement:
TYPE "THE AGE OF ",APR(UN,NAME)," IS ",(AGE)
is equivalent to the example cited earlier.
As another example, a patient file may be organized as illustrated in Fig. 5, with the various fields at the top level of subscripting indicating the individual patients, a second level of subscripting partitioning a particular patient's record into subfieids, and yet another level expanding one of the subfields, "diagnostic impressions," into the individual diagnoses recorded for that patient. Figure 6 then illustrates a simple retrieval program which shows how straightforward it can be to utilize such a data base despite the relative complexity of its organization.
The philosophy of MUMPS requires that reference to all file information be done symbolically, in the syntax of hierarchical global arrays. This replaces the classical manner of sequentially accessing record files on secondary memory devices. Instead, an attempt is made to logically map the content and structure of the tree-like data arrays into the physical storage medium of the system. The general technique is to map logical information at a specific level of an array into directories of fixed size blocks chained together linearly to contain all the data values stored at that level, and all the pointer words which link it to the chains of the next lower level. The implementation of this design requires a careful consideration of the timing and size constraints of the physical device in relation to the overall system. The actual memory device used in the system is a large fixed head disk. The organization of this type of disk is two dimensional, wherein any physical block has a track and a segment coordinate. Initially a set of free lists are formed which chain all blocks possessing the same segment address together. Whenever a continuation block at the same level or a header block at a new level is required, the appropriate block in the free list whose segment address is a few segments away is utilized. This method insures that accessing any element of a previously formed global array requires not much more than the average access time of the disk unit. As a consequence, the time required to retrieve a particular datum is virtually independent of the depth of subscripting required to specify the datum. Space is conserved by utilizing small sized physical blocks such that at any subscript level an average of one continuation block is required. When data is updated, care is given to repack and sometimes reorganize the individual data elements within a chain to insure maximum utilization of space for variable length data. Whenever a part of the global structure is deleted, it is passed to the garbage collector routines to be disassembled from tree-like chains back into linear chains and appended to the appropriate free lists. This is done during periods of low CPU activity so as to avoid competition with the active programs.
Once a block of data accommodating a single level of subscripting is referenced, it is maintained in core memory until a reference is given to a different block by the program. Use of the naked variable then permits other data at the same level to be referenced merely by specifying a terminal subscript, so that once a level is reached, often no further disk access need be made to manipulate associated information. If any data in a block is altered, it is only written back on the disk when a reference is made to a block other than the one that is in core memory, or when a CLOSE command is given.
CONCLUSION
The convenience occasioned by the utilization of a high-level language with symbolic referencing capability for data stored in complex tree structures on peripheral storage has greatly simplified the development of application programs for clinical data management. This is the only system that we know of, on a computer of medium or small scale, which supports such extensive file manipulation, string handling, and input/output flexibility. It is the only system we have encountered on any computer which allows all these manipulations to occur entirely in a high level language. This system has been used at the MGH for all of our programming research and development activities. Equally important, because of its compactness and efficiency in this environment, we use it for the implementation of our service programs, including a chemistry laboratory reporting system,18 a patient history taking system, and a number of programs for physician entry of narrative record information.
An advantage of this approach to clinical data management over the use of a large commercially available general purpose time-sharing computer, with its complex operating system, has been the increased flexibility that can be built into a system rather than designed around. At the same time, both the flexibility required for research and development and the efficiency required for service operation can be achieved with a computer whose size and cost are well matched to the requirements of the problem area.
REFERENCES
1. LINDBERG, D. A. Collection, evaluation, and transmission of hospital laboratory data. Meth. Inform. Med. 6, 97-107 (1967).
2. PRIBOR, H. C., KIRKHAM, W. R., AND HOYT, K. S. Small computer does a trig job in this hospital laboratory. Mod. Hosp. 110, 104-107 1968.
3. BARNETT, G. O. AND HOFMANN, P. B. Computer technology and patient Care: experiences of a hospital research effort. Inquiry V: 51-57 (1968).
4. HICKS, G. P., GIESCHEN, M. M., SLACK, W. V., AND LARSON, F. C. Routine use of a small digital computer in the clinical laboratory, JAMA 196, 973-978 (1966).
5. JACOBS, H. A natural language information retrieval system. Meth. Inform. Med. 7, 8-16(1968).
6. PRATT, A. W. AND THOMAS, L. B. An information processing system for pathology data. "Pathology Annual," VOL 1. Century Appleton, New York, 1966.
7. BARNETT, G. O. AND GREENES, R. A. Interface aspects of a hospital information system. Ann. N. Y. A cad. Sci. (in press).
8. YODER, R. D. Preparing medical record data for computer processing. Hospitals 40, 75-76 (1966).
9. WEED, L. L. Medical records that guide and teach New Eng. J. Med. 278, 652-657 (1968).
10. SLACK, W. V., HICKS, G. P., REED, C. E., AND VAN CURA, L. J. A computer-based medical-history system. New Eng. J. Med. 274, 194-198 (1966).
11. MAYNE, J. G., WEKSEL, W. AND SHOLTZ, P. N. Toward automating the medical history. Mayo Clin. Proc. 43, 1-25 (1968).
12. KIELY, J. M., JUERGENS, J. L., HISEY, B. L., AND WILLIAMS, P. E. A computer-based medical record. JAMA 205, 571-576 (1968).
13. TEMPLETON, A. W., REICHERTZ, P. L., PAQUET, E., LEHR, J. L., LODWICK, G. W., AND SCOTT, F. I. RADIATE--Updated and redesigned for multiple cathode-ray tube terminals. Radiology 92, 30-36 (1969).
14. PENDERGRASS, H. P., GREENES, R. A., BARNETT, G. O., POITRAS, J. W., PAPPALARDO, A. N., AND MARBLE, C. W. An on-line computer facility for systematized input of radiology reports. Radiology 92, 709-713, 1969.
15. HALL, P., MELLNER, C. AND DANIELSSON, T. J5-a data processing system for medical information. Meth. Inform. Med. 6,1-6 (1967).
16. DAVIS, L. S., COLLEN, M. F., RUBIN, L., AND VAN BRUNT, E. E. Computer-stored medical record. Computers and Biochemical Research 1, 452-469 (1968).
17. SHAW, J. C. JOSS: A designer's view of an experimental on-line computing system. "AFIPS Conference Proceedings," (1964 FJCC), Vol. 26, pp. 455 464. Spartan Books, Baltimore, Maryland, 1964.
18. KATONA, P. G., PAPPALARDO, A. N., MARBLE, C. W., BARNETT, G. O., AND PASHBY, M. M. Automated chemistry laboratory: Application of a novel time-shared computer system. Proc. IEEE (in press).
* Supported in part by grant HM-688-01 from the National Center for Health Services Research and Development and in part by contract PH-43-68-1343 with the National Institutes of Health.
 If you have any other document we could include here, send an e-mail
to chribonn@softhome.net.
If you have any other document we could include here, send an e-mail
to chribonn@softhome.net.
Last Updated: 26 October 1996
The Index or Go UP