
MPP( Massive Parellel Processing ); The hardware platform of VLDB( Very Large Data Base ). Oct, 1998
- written by Kevin D. Shim
PROBLEM OF STATEMENT
Selecting server hardware is one of the most daunting tasks for information systems directors and network managers. IS managers are struggling with rapidly growing data warehouses that cannot be handled by more conventional architectures. In addition, vendors are wrestling with how to help customers with this problem now, as the first wave of client/server systems encounters bottlenecks associated with limited processor speed, disk I/O and network bandwidth.
BACKGROUND INFORMATION
Right sizing sometimes means bigger
In the last few years, the word "rightsizing" has had various meanings. One implied the demise of the mainframe and a move to more cost-effective client-server systems; by implication, smaller was better. Some customers, however, say that rightsizing means bigger, and the growing demand for MPP systems affirms this. This isn't surprising, since MPP systems combine the cost-effectiveness of client-server technology with performance far beyond mainframes. Customers generally give one of two reasons for going to MPP. The first is to mine customer information-such as buying trends, service histories and satisfaction surveys. This often requires more processors to access more data in a critical period of time than is possible with traditional mainframes or client-server networks. The second reason for going to MPP is to increase efficiency. The superior economics of MPP, due mainly to lower hardware, programming and system administration costs, allows the customer to solve problems at significantly less cost than traditional systems. Unlike mainframes or other large servers whose scalability (performance expansion) is limited by their tightly coupled architectures, the MPP System can be configured with hundreds of processors and terabytes of disk storage. Software breaks problems into separate tasks and distributes them among the processors, which work on them in parallel. Due to its loosely coupled message-passing architecture, system performance scales (increases) as processors and disks are added. A key benefit of this architecture is that customers can grow their systems in small steps, thereby upgrading them in place.
LITERATURE REVIEW
Selecting a proper VLDB hardware platform: SMP, Clustering, NUMA, or MPP
The answers to very large database (VLDB) for higher data warehouse performance and scalability that vendors are providing include symmetrical multiprocessing (SMP), clustering, Non-Uniform Memory Access architectures (NUMA), massively parallel processing (MPP). SMP systems have a common operating system and common memory. With SMP, the biggest bottleneck is the memory bus bandwidth. One way to get past this is to cluster systems together to increase performance or availability. Clustering can be expanded so the total number of CPUs far exceeds the CPU limit on SMP boxes. However, performance improvements are not linear, and the bandwidth of the interconnection between the nodes themselves is often too low to sustain high-performance gains. The NUMA approach is a sort of hybrid between SMP and clustering. NUMA avoids the memory bus bottleneck issue in SMP by essentially breaking the bus into several smaller buses. The drawback is that NUMA is not as mature as SMP. For near-linear performance gains, MPP systems offer the best option. Although it is significantly more expensive and more complex to manage than the other architectures, it does give users virtually unlimited node expansion and a single view to the application and users.
SMP
If users want something that works today, they should go with SMP (Settle, 1995). What's best about an SMP solution is that users can transparently scale up servers. Newburn and Shen (1997) insists that no modifications should be required to the application programs or database management systems currently running on single-processor versions of the same operating system. As users need more processing power, users can add processors up to the physical limit of the server that they choose. SMP, most of which accommodate between two and 32 CPUs, can meet the huge demand for growth of a data warehouse. Serafini (1997) said in his article that SMP servers let users tie multiple processors together and harness their combined power in a relatively inexpensive and painless manner. Users can start small and scale up quickly by simply adding more processors. Users can run multiple applications in the same box using the different processor, all of which share a memory pool. And users can add processors without having to tweak either the application or the database (Brewer, 1997). The typical structure of SMP would be like this:

But if users try to scale beyond the system and if many users need to access it, SMP performance gains become less dramatic and more costly. The biggest bottleneck is the memory bus bandwidth. As the CPU count increases, so does the amount of traffic on the bus. This eventually causes system throughput to decrease dramatically.
Clustering
One way to get past the memory bus bottleneck is to cluster systems together to increase performance or availability. For instance, by tying together two 16-processor SMP servers, or "nodes," users can build one 32-CPU configuration server and significantly increase performance. And this is cheaper than building one large 32CPU system, Brewer (1997) said. The mechanism of clustering is the following:

Clustering can be expanded so the total number of CPUs far exceeds the CPU limit on SMP boxes. Digital Equipment Corp. (1998) for years has been offering OpenVMS clusters that can tie together up to 96 nodes - each of which can be an SMP system. In theory, at least, users can get significant performance gains with each additional node. But each node has its own memory pool and system bus, which means programming has to be done to coordinate the communication of information and sharing of data across the various nodes in the cluster. Thus, performance improvements aren't linear, and the bandwidth of the interconnection between the nodes themselves is often too low to sustain high-performance gains. Some vendors - such as Digital with Ts Memory Channel interconnection and Tandem Computers, Inc. (1998) with its ServerNet technology - offer specialized interconnect technology to overcome this bottleneck. But for the most part, Park (1996) said users rely on clustering methods more for high-availability purposes than for performance scaling. For instance, two or more nodes can be tied together in one cluster so that if one node fails, another node takes over automatically. That guarantees high availability of the hardware and applications.
NUMA
The NUMA approach is a sort of hybrid between SMP and clustering. According to Dandamudi and Cheng (1997)'s research, NUMA arranges multiple processors in a server in small groups of processors. For example, the Ir-processor server of Sequent Systems can be arranged into a cluster of four nodes with four processors each. That technique lets users tie together more processors in one enclosure than SMP does. Sequent Systems, Inc. (1998)'s NUMA servers, for instance, can support up to 252 Intel processors in one box. The typical structure of NUMA would be like this:
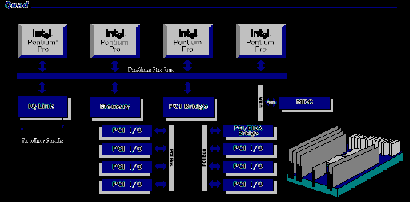
NUMA is basically making it easier and a lot cheaper to build really large SMP boxes (Wang & Chang, 1997). As with SMP, users don't have to tweak applications or databases each time additional processors are added. Garvey (1996) insists that NUMA avoids the memory bus bottleneck issue in SMP by essentially breaking the bus into several smaller buses. The processors within each node in a NUMA server communicate with one another using those smaller SMP buses. And each of the nodes communicates with the others using fast interconnect technologies. The advantage of NUMA is that it doesn't force people into a new programming model. Users can take an SMP application and put it on NUMA, and it will run. The drawback is that NUMA isn't as mature as SMP. And a lot of its success depends on how quickly and easily each of the nodes in the system can communicate and share data. There is a concern that we are pushing the technology envelope a little bit.
MPP
For near-linear performance gains, massively parallel systems offer the best bet. MPP is significantly more expensive - some systems start at more than $5oo,ooo, compared with about $240,ooo for an entry-level Sequent NUMAQ 2000 - and more complex to manage than the other architectures. But it gives users virtually unlimited node expansion and a single system view to the application and users (Edwards, 1995). According to Babcock (1996), in an MPP configuration, hundreds, if not thousands, of processors can be tied together. Each has its own memory and bus and is capable of handling its own tasks and communicating with the others via highly specialized interconnects and switches. But the applications and the database have to be tweaked extensively to run optimally on MPP systems, Dandamudi & Cheng (1997) warned. For instance, the applications themselves often have to be "parallelized" so specific tasks are allotted to specific processors or sets of processors based on computing requirements.
Choosing a right repository for VLDB
Considering all the aspects; performance, price & scalability, SMP & MPP are currently most appropriate for the very large data warehouses or very large databases. SMP is when multiple processors share either memory, disk storage units or both. This system works will with about up to 16 processors and is best for small- to medium- sized database systems. MPP is especially designed to handle very large database systems. These machines often have processing engines that have their own copy of the operating system, memory and disk storage units. In the commercial market, MPP is primarily used in niche roles such as data warehousing and server consolidation. But some vendors hope to widen the application portfolio by changing MPP's "share nothing" architecture into a hybrid with SMP-like shared resources. Most workloads in the commercial market, particularly [database management systems], favor shared-resource nodes.
DISCUSSION OF ISSUES
MPP or SMP?
Choosing an architecture depends on which type of application a company wants the technology to support, the amount of data that will be accessed, the number of users accessing the system and the complexity of the data analysis. When do you need MPP? If your applications run on SMP, don't bother with MPP. For example, SMP is a better choice than MPP if you are running applications that require many ad hoc queries, because SMP nodes communicate easier than MPP nodes. SMP also may be the right choice if you're running online transaction processing systems and don't expect them to grow a lot. Where enterprise-wide data warehousing, involving massive amounts of data, lends itself to MPP, on-line transaction processing (OLTP) for a bank's ATM network, for example, performs better on SMP. So if a customer is pushing a button out there [on an ATM] for a transaction to be executed, the fastest and best way to execute that transaction is to run it on the fastest engine you have, which is generally on an SMP. MPPs have more processors, but each one is generally a little bit slower. So it does better with the kind of work that can be effectively done by many parallel processors. SMP, "shared everything" architecture, is the predominant bank choice, because the technology is more established (i.e., it's been around longer); a greater number of applications and tools exist to support it; the hardware partitions the data, rather than software programmers and database administrators, ensuring minimal bank involvement in processing mechanics; and it's faster for certain compute-intensive requests, such as trading instrument analysis and sub-second transaction processing. While SMP is the predominant bank choice, MPP generally eclipses SMP in scalability. MPP is able to get the most out of each of its processors and can support a virtually unlimited number of CPUs. MPP is based on a "shared nothing" architecture, means that MPP processors do not share memory or disk space, and rather than communicating along a single interconnect, each processor talks directly to the others. As a result, MPP does not suffer from the data bottlenecking that plagues SMP systems when processors send more data onto the interconnect than the bus can handle. MPP, therefore, generally eclipses SMP in scalability--although many SMP vendors assert that by combining SMP systems, which can incorporate as many as 64 processors, into clustered nodes, SMP is just as scalable as MPP. IBM, for instance, is the only vendor that operates in both the commercial and scientific markets. IBM has installed several 5oo-node MPP systems in the scientific community and has dealt with the complexities of designing software to manage them. Banc One currently employs several MPP systems for financial analysis, decision support, customer analysis, enterprise warehousing, and high-speed transaction processing. The bank's high-speed transaction processing runs on MPP, rather than SMP, because the system is processing point-of-sale (POS) transactions, which are small, simple requests that come in at a high volume. That means you have all of these multiprocessors working on [the transactions] at the same time, and they're not too complicated, so these slower engines do them just fine. On the other hand, Banc One is using SMP architecture to support its credit card company in rapid decision support. When a customer requests a credit limit increase, that transaction is sent through a complex algorithm which then incorporates data pulled in from credit bureaus. The analysis can take no more than 10 seconds. That takes all the engine speed they have, so it works better on a computer that has fewer processors, but bigger or more powerful ones, which are generally SMPs. On the trading side, Deutsche Bank is also now employing both MPP and SMP. Use of MPP is a relatively new development in trading applications. They built their security clearance system on an MPP. They chose MPP because the volume and responsiveness and the type of application and database required [MPP's] economies in scalability. On the other hand, the bank is building a new foreign exchange system on SMP because the complex analysis and database run best on a high-powered engine.
WHY MPP?: Motivation to use MPP
Information is the fuel that drives business today. To stay competitive in an increasingly fast-paced world, businesses are expanding into global markets, reengineering their operations and getting closer to their customers. The faster a company gets information, moves it to where it's needed, and uses it to make better decisions or perform vital functions, the sharper its competitive edge. Unfortunately in many companies the most valuable information is buried in miles of magnetic tape or distributed across a universe of uncoordinated systems, rendering it useless. Even when the information is accumulated on-line, traditional mainframe computers don't have the power to process it fast enough. That's why businesses are turning to massively parallel processing (MPP). Massively parallel-processing systems apply the power of thousands of processors, working in parallel (simultaneously), to turn huge quantities of data into actionable information, enabling customers to implement applications that were previously considered impractical. For example, * Wal-Mart, the nation's top retailer, allows its major suppliers to access its AT&T MPP system for detailed daily sales information from its stores, and lets the suppliers decide when and where to replenish inventories--a win-win arrangement for both Wal-Mart and the suppliers. * In the aftermath of the devastating 1994 Los Angeles earthquake, Bank of America was able to use its AT&T MPP system to analyze its mortgage-loan database and determine within minutes the extent of its potential loss. Ironically, the success of the PC, which has driven the the availability of fast, low-cost microprocessors, and advances in storage and communications have now made MPP economically feasible.
How WAL-MART Leverages MPP
Wal-Mart, the leading U.S. retailer--with 1993 sales of $67 billion and a 30 percent annual growth--has applied MPP in managing its business. Wal-Mart's current AT&T system comprises 476 processors and 1,095 disk drives housing a Teradata database of 2.7 terabytes (trillion bytes). Twenty-million records, representing item-level sales data from each of 2,100 stores, are beamed daily to this system to update a table holding a full year's worth of detailed sales data. By querying this table, Wal-Mart's buyers can analyze sales trends by item and by store, and can make informed decisions on purchasing, pricing and special promotions. Wal-Mart's replenishment system automatically triggers orders to manufacturers based on the daily sales data, making it unnecessary to inventory large quantities based on predicted demand. The idea is to let the customer control Wal-Mart's business. The result is that in spite of its size, Wal-Mart can manage itself one store at a time, getting the right product mix to each store at the right time--often the next day. Shelves are kept fully stocked and inventory costs are lowered, resulting in lower prices, which in turn bring in more customers. One of the keys to customer satisfaction, Wal-Mart believes, is whether a store has the items you want in stock. Perhaps the most advanced aspect of Wal-Mart's system is the way it works with its suppliers. Over 2,500 suppliers have on-line access to all information about their products in Wal-Mart's purchase database, and can perform their own analysis of buying patterns. In many cases, the suppliers are responsible for managing their inventory at each store and identifying opportunities for new items for local merchandising.
<;/p>
MPP in banking
Bank of America, the nation's second largest bank, uses its AT&T MPP system to consolidate information from 36 million customer accounts from 23 different operational systems. This 600-gigabyte database includes data from checking, savings, time deposit and bankcard accounts, as well as real estate, consumer and commercial loans. Using this database, Bank of America analyzes trends in its relationships with its customers to determine which are likely to purchase a particular bank product or service. The bank can thus tailor promotional mailings to the interests of specific customers. The retention of detailed data has also provided some unforeseen benefits to Bank of America. After the 1994 Los Angeles earthquake, BOA's residential group was able to go in and see by zip code how many and what types of real-estate loans the bank had in those areas where the earthquake hit.
Major technologies in MPP
The next-generation network: BYNET
An MPP system, such as the 5100M of NCR SYSTEM (NCR Corp., 1998), uses a loosely coupled design in which all processor subsystems (nodes) have local dedicated memory and separate copies of the operating system. Communication among processors is via the BYNET high-speed interconnection. This allows dozen, even hundreds, of processor nodes to work together as one system, enabling the largest database applications in the world. The 5100M has immense computing power for slicing and dicing multiterabyte data bases. Data is not managed within a single subsystem, but distributed to many. Subsystems scale linearly, so that workload throughput increases with the number of processing subsystems. This approach quickly converts data to information by simultaneously using all the subsystems to gather information for the database. The parallel processing performance provided by the 5100M server, coupled with the industry's leading databases, brings outstanding solutions. In addition to the AT&T Teradata(R) parallel database, the 5100 supports merchant databases including Oracle, Informix and Sybase. BYNET is the key to coordinating the multiple processor subsystems. BYNET also scales linearly as processors are added to an MPP system, giving the system unparalleled database connectivity and power for growth to tens of terabytes. As in the 5100C, the AWS is the single point of system management for the 5100M. The AWS allows easy monitoring of processor subsystems, disk subsystems and MPP network connections to each processor no matter how many cabinets the system contains. The foundation of the 5100M is a single processor subsystem identical to the 5100S subsystem. Application development may be started on a 5100S and implemented on a 5100M, providing a smooth transition through a single upward migration. In mainframes, growth in processing power usually means installing a large upgrade or replacing the system. The 5100M, however, can be expanded incrementally to add more power, new users, and new applications of database capacity to accommodate business growth. BYNET is derived from a folded banyan network topology, which provides multiple switching paths to interconnect all the processor subsystems in the 5100M. (Banyan networks are named after the Indian banyan tree whose branches intertwine in a pattern that looks much like a graphical interconnection pattern of BYNET.) Initially, BYNET will be capable of interconnecting systems using up to 16 nodes. Designs now in the works are planned to increase this up to 512 nodes. BYNET works much like a telephone network where many callers can establish calls, including conference calls. For example, one processor in the system calls another and a two-way circuit is established between them. Application data is transmitted over the outgoing circuit, called the forward channel; message status information, such as acknowledgment, is sent over the incoming circuit, called the back channel. Nodes in BYNET can call other nodes in this way, or a node can establish a broadcast channel to all other nodes simultaneously. All receiving nodes will send acknowledgments to the calling node over the back channel, which merges them into a single reply for the calling node. Thus, the calling node can assign specific parallel tasks to all the others and can determine when the last node has completed its task. BYNET is linearly scalable: whenever a processor node is added to the system, a full increment of interconnection bandwidth and new network paths are also added. High availability is ensured by dual redundant networks, which are standard in a BYNET interconnection. Multiple connection paths can be established between any two nodes so if one path is lost, the connection is simply routed over another path. Faults are detected and the network is reconfigured automatically with no interruption to normal operation of the application.
Parallel relational databases & Distributed transaction processing
Software is the key to building a successful MPP system, which must be robust enough to meet the needs of large corporations and operate at the heart of their client-server networks. Software must also shield the system's users from the complexities of its parallel architecture, providing a single-system view to the outside world. The MPP system such as the system 3600 of NCR Teradata (NCR Corp., 1998) uniquely achieves these goals with an integrated software set comprising industry-leading parallel database and transaction processing capabilities, enterprise-class networking and system management facilities, and extensive fault-resilience services. A basic requirement for MPP systems is that they offer parallel database management capabilities to achieve high performance and present a single system view to the application. Relational databases, and the structured query language (SQL) used with them, offer tremendous opportunities for parallelism and consequent speed-up of query processing. A large table, for example, can be spread across many nodes, and a query that must pass through the entire table for an answer can be broken into sub-queries that each node executes in parallel. The mechanism is the following: Large businesses are depending more and more on the ability to immediately access and update their critical data from anywhere in the enterprise. The key middleware component of the 3600 that makes this possible is the Top End(R) software subsystem, AT&T's open distributed transaction management system, which manages the entire transaction processing environment. It shields the customer's applications from the complexities of the client-server network and of database interactions across multiple systems. Top End schedules applications and distributes messages among the application components, freeing the application programmer to focus on the business aspects. Top End maximizes transaction parallelism by replicating applications across the nodes of the system, and automatically balancing the transaction workload among the nodes, thereby achieving performance levels in the thousands of transactions per second. To meet a business's information needs, the System 3600 has many features that ensure a high level of system availability; the loosely coupled architecture allows it to recover from faults quickly. Extensive fault monitoring and detection are provided in hardware and software, and individual nodes can be brought in and out of service automatically without disrupting system operation.
Understand Amdahl's Law
Amdahl's law is the equation that defines the limit of speedup for a particular application. Its basic form is: TN = T1(p) / N + T1(1-p) , where TN is the time a task will take using N processors; T1 is the time a task takes using one processor; and p is the percentage of an application that can be parallelized. The central idea is that any task has a portion that is sequential (for example, dividing a single query into subqueries and then distributing the subqueries to various processors), and a portion that can run in parallel (for example, the actual execution of the subqueries on different processors). If a task requires 200 seconds on a single processor, and 95 percent of the task can be parallelized, there still remains 10 seconds that cannot be parallelized. Thus, no matter how many processors you add, you cannot complete your task in less than 10 seconds. In this case, the speed-up limit is 20x. In general, the speedup limit as N gets very large is 1/(1 - p). This has important implications, because it contradicts the popular belief that as you add more processing nodes, you will continue to see additional speed-up. However, the speedup limit formula also points out that if p is close to 1, even small increases in the value of p will yield very large increases in the speed-up limit.
Observing success factors for MPP
Massive parallel processing (MPP) is maturing. Currently, there's a lot of experimentation going on with the design of MPP machines-many vendors are delivering numerous machines, and every thing from the processor design and operating system to the interconnect topology differs among vendors' offerings. Even more important, however, is that customers are using varying approaches to apply MPP technology to business problems. Some of these methodologies have worked, and some haven't. In order for MPP to succeed and gain ever-widening acceptance, the market must identify a relatively small but robust set of approaches-in essence, it must move toward standardized approaches to implementing MPP systems. These standard approaches are called " success factors".
Focusing on Business Needs, Not Technology
There's a feedback relationship between business needs and technology, because new technology gives you new capabilities, and therefore extends your potential menu of applications that can be built. But, the successful MPP users were those who could justify pursuing new opportunities with real business needs. MPP can be used as the best when it is the only possible solution. In accordance with focusing on the business problem, successful adopters made sure that, before deciding to use MPP, all other technologies were ruled out for valid reasons. Users should not use MPP simply because it is the best solution, but rather because it is the only solution. One example of this comes from American Express. For American Express, MPP was the answer. It was the only solution that presented enough raw horsepower to address its problem. Thus, they adopted the technology, applied it to their problem, and now runs its set of database mining queries in half a day. Addressing the People Issues Unfortunately, there does not seem to be any consensus as to what are the effective or ineffective ways of handling the people issues involved with MPP installations. A possible answer is that effective solutions differ depending on the corporate culture. The best advice is to be cognizant of the issues, and prepare for them in three ways: 1. Build an adequate personnel infrastructure; 2. Manage reasons for project support and sabotage; and 3. Set user expectations.
Building an Adequate Personnel Infrastructure
If your MPP implementation is going to be successful, you must ensure that your organization has the appropriate technical and support infrastructure in place. This means that you must adequately train developers, as well as system administrators and support personnel. MPP vendors often offer this training.
Managing the Support/Sabotage Wars
Within a corporation, all people who will be affected by the adoption of MPP-from management to developers to end users-have personal reasons for either supporting or sabotaging the project. Supporters tend to be vocal about their support, but the sabotage is much subtler. It is often not a conscious effort, but manifests itself in the form of complaints about project scope, functionality, and timelines, or delays and low morale.

Setting User Expectations
It is extremely important to set users' expectations correctly. Successful MPP users typically chose one of two ways of doing this effectively. The first method entails minimal end-user involvement; that is, letting your end-users give input into the application design. Aside from added functionality and/or improved performance, of course, the technology change is intended to be transparent to the end-users. But knowing their needs and desires is important to the success of the project.
CONCLUSION: MPP ?the best choice for VLDB
Because MPP is able to get the most out of each of its processors and can support a virtually unlimited number of CPUs, organizations planning for high-volume data storage--initially more than 150 gigabytes--such as in enterprise-wide data warehousing or risk management systems, tend to opt for MPP systems. And even though SMP systems can handle 150 gigabyte volume, industry sources suggest that banks beginning at the 150 GB level will ramp up to a terabyte so quickly that they might as well save themselves the transition costs, and go with MPP. If users look at applications in the field, like Bank of America, which has about 1.5 terabytes, they should go using MPP. They have more than a terabyte of data volume, which necessitates MPP architecture.
Performance
On an MPP machine, a very large table would be split into pieces and distributed evenly to all processing units. The ideal solution is to divide and conquer. When users query a mainframe system, users have one query going against a very large set of data. On the contrary, when users query an MPP machine, the machine broadcasts the query over the I/O bus. Each of the processing engines (PE) queries against their DSUs to find the answer. It is easy to see how an MPP machine with 100 PEs can find an answer against a very large table faster than a single query going against a very large set of data. MPP machines also have the ability to be fault tolerant. This means that they can continue to operate after a piece of the hardware has failed. This feature is done in conjunction with the DBMS. They can carry duplicate copies of the rows for each table on each of the PEs.
Scalability
MPP machines can also be very modular and upgradeable. This means that the system has the scalability to grow to the size you need. This can be of great importance. It is not unusual to see these machines double in size every two years. It is fairly easy to add additional PEs or nodes to the system. An MPP system should not only be able to be channel connected to a host computer system, but connected to a PC-based LAN system as well. These utilities should be able to run as host production jobs or from the LAN. The point is that these utilities or tools will have an immediate impact right on the bottom line by reducing expensive database administrator (DBA) and programmer time.
Price
What this all means is a lower maintenance cost for this type of DBMS. In order for an MPP machine to fully utilize the massive parallel-processing concept, it must use a DBMS that was built to perform every database function in parallel. This means you want it to be able to insert, delete, update, select and do all of its operations in parallel. This will be reflected in the performance that the system can deliver, in the speed of queries, number of concurrent users and the size of the tables it can handle. If the DBMS is built to be parallel, then it should be easy to double the size of your system when necessary. The interest in data warehousing and what a MPP system can do with all that data is an exciting and developing field. No other technology has the capability of handling terabytes of data in a cost-effective manner.
APPENDIX A: The current market trend for VLDB Platform

?#060;/p>
APPENDIX B: VLDB/MPP Warehousing questionnaire
VLDB/MPP warehousing questionnaire
The following questions will help the researcher know about the desirable hardware platform for VLDB warehousing. Please answer each question. Thank you for your help.
1. What does your company do? _____________________________________________
2. Please specify your company's size? ______________________________________________
3. What is your position in your company? ____________________________
4. Which kind of hardware platform are you considering as your database warehousing? SMP____ MPP____ NUMA___ Clustering___ Other_________________
5. What makes VLDB special? cost-effective_____ huge size_____ error-tolerable______ transaction capability_____ other_____________________________
6. Which aspect will you mostly consider when you choose a hardware flatform of database warehousing? Performance_____ Scalability_____ Price____ Other________________
7. Were you involved in the movement from the legacy DBMS to VLDB, and if yes, has the system lived up to your expectations? ___________________________________________________________________
8. If you are a developer of your company's database warehousing for VLDB, which hardware platform will you choose? SMP_____________ MPP________________
9. Why did you choose it? ___________________________________________________________________
10. If you do not choose MPP, what is the reason? ______________________________________________
REFERENCES
Andy, B. (1998). MPP: A Strategic Weapon. http://www.dmreview.com
Babcock, C. (1996). Wordls collide. Computerworld. 30(24), A2-A4.
Biggs, M. (1997). Hallmark Cards' MPP system handles a large decision support database with complex queries. I/S Analyzer. 36(6), 7-10.
Brewer, E. (1997). Clustering vs. SMP. Data Communications. 26(9), 90.
Bull, Katheringe (1995). Informix enters MPP fray. Informationweek. (523), 78.
Dandamudi, S. P. & Cheng, S. P. (1997). Performance impact of run queue organization and synchronization on large-scale NUMA multiprocessor systems. Journal of Systems Architecture. 43(6,7), 491-511.
Edwards, J. (1995). The speed ticket. CIO. 8(12), 62-66.
Garvey, M., J. (1996). Multiprocessing war a draw? Informationweek. (607), 100-104.
Godlberg, M. (1996). The big dig. Computerworld. 30(24), A6-A10.
Hitachisoft Inc. (1998). Parallel relational Database. http://www.hitachisoft.com/jp1/hir_head.html.
Ncr Corp. (1998). NCR Teradata RDBMS. http://www3.ncr.com/product/teradata/index.html
Newburn, C. & Shen, J. P. (1997). Post-pass partitioning of signal processing programs. International Journal of Parallel Programming. 25(4), 245-280.
Park, C. & Hwang, K. (1996). Performance analysis of hybrid disk array architectures to meet I/O requirements. Journal of Systems Architecture. 42(1), 37-53.
PiSMA (1998). PiSMA Architecture Description. http://aiolos.cti.gr/pisma/pismadoc.html
Serafini, R. (1997). SMP-like fixed bus vs. building block style. Computer Technology Review. 17(8), 24.
Settle, D. (1995). Scalable parallel processing (SPP) fulfills and exceeds ?MPP's one-bright promise. Computer Technology Review. (Special Supplement), 17-22.
Wang, Y., Wang, H., & Chang, R. (1997). Clustered affinity scheduling on large-scale NUMA multiprocessors. Journal of Systems & Software. 39(1), 61-70.
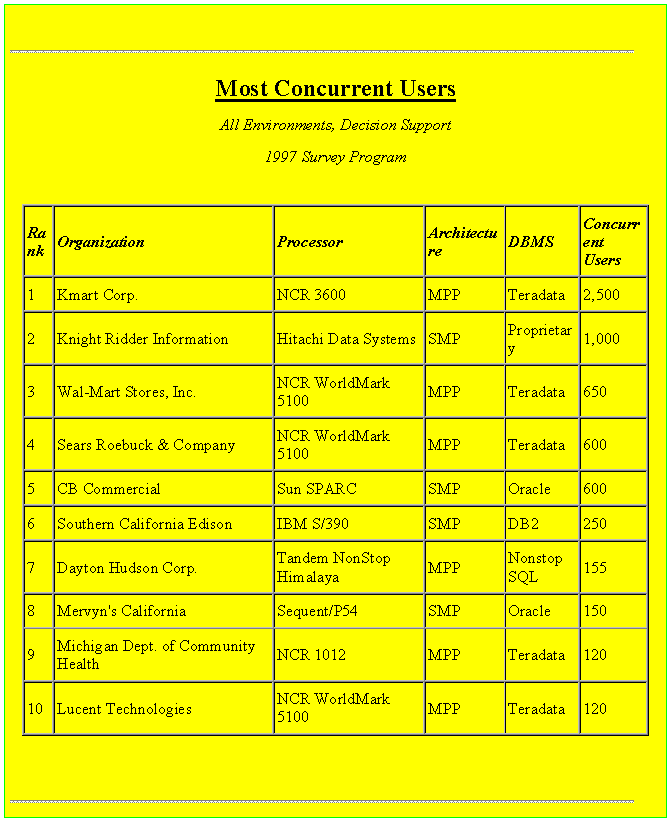
Winter Corp. (1998). Largest Database Size, All Environments, Decision Supports. http://www.wintercorp.com/toptenwinners/table7.html

Copy rights, November 13, 1998. Kevin D. Shim