| Contents |
| 1. Introduction |
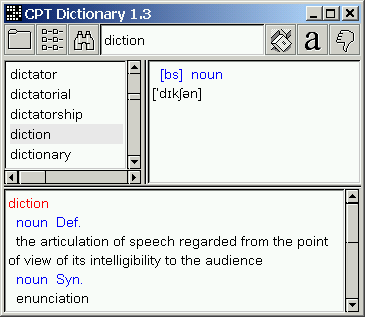
The distribution contains two sample dictionaries, just to test the installation:
You can check the web page http://geocities.datacellar.net/cptshareware for more word lists and dictionaries.
You should have minimum 600 KB of disk space for the program and the sample files. The RAM requirements are according to your OS in most cases (but for example, if you want to open a 20000000 words dictionary in Browse Style, your should have 256MB RAM.)
The program can do extremely fast and incredibly slow searches depending of the settings. The rules of thumb are:
In any text field/area of the program you can click with the right mouse button to show the Popup menu having the following, depending of the context, items:
Note: For the Linux version to select an item from the Popup menu, move the mouse pointer over the item and then release the right button.
The communication with the clipboard is in Unicode
and in logical order when the dictionary is stored
in logical order (RTL scripts).
For some extensions for Linux see
the flags in 'Input Tab',
'Search Options' dialog.
| 2. Select Dictionary |
After starting the program, click on the left most button to open a dictionary and/or to add new one to the lists. You can do searching in one or more opened dictionary files.

The list 'Main' is for all your dictionary files. To add a file click on the 'Add New' button and select a file via the 'Open' dialog. To delete a file from the list click on the 'Remove Selected' button and the current selected file will be deleted from the list. The selected file from the main list will be the main dictionary opened when you click on the 'OK' button.
The list 'Additional' is for the additional files to be opened. Note that you can add files to the additional list only from the main list - select a file in the main list and click on the 'Add Main Selected' button for the additional list. All files from the additional list will be opened only if you enable the flag 'Additional Dictionaries' in 'Search' tab from the 'Search Options' dialog. The program may refuse to open an additional dictionary if it is not 'compatible' with the main dictionary. E.g., if the main is Farsi (RTL script) and the additional is English-Russian (LTR script), it will not be opened.
The radio button group 'Open main selected on start up' allows to choose one main dictionary and to forget about this dialog. 'None' is used to clear any selection made, without browsing the whole main list.
The radio button group 'RAM used and search speed' is almost obsolete. In most cases you should select 'Low' (the packed CTrees now have reasonable speed, and the inverted indexes will force 'Low'). If you select 'High/Medium' for big CTree with clues, you will really gain in speed for multiple searches in 'Search Style', but the opening of the dictionary could be very slow.
When you click on the 'OK' button, the selected main dictionary will be opened and available for searching/browsing, and optionally, the additional dictionaries will be opened for searching. The changes in the additional list are saved unconditionally - even if you click on Dismiss/Close buttons. This way you can change the list without reopening the main dictionary.
| 3. Display Options |
The second button from the bar will start a dialog with the following options:

'Search Style' means no display list and all matches from the searching will be shown.
'Browse Style' means to create display list and only the first match will be selected. When you click on a word from the browse list (or search a word), you will see the tags and clues linked to this word or the variants of the word if in 'Variants' mode. If there are additional dictionaries opened, the selected word will be searched there as well.
'Sort' will force the 'natural' sorting of the display list.
It will be done if the display list contains upper and
lower case letters, and if the dictionary has been created
using 'Strict Alphabet' and 'Locale Sorting'.
'Ignore Accents' is option for the natural sorting only.
'Words' will switch the main search/browse list to the normal mode (words -> clues).
'Definitions/Clues' will switch the main search list to the clues if available. Note that the searching in clues using 'Search Style' means to scan sequentially all CTrees in the dictionary, which is the most slowest mode that we can imagine. For normal speed, use 'Browse Style'.
'Browse with Inverted Index' will create/use the supporting inverted index when searching in clues. In this mode when you select a clue (click or search), you will see all words, which have links to this clue. If the flag is not set, you will not see the words, but you will save many resources (time and memory).
If the dictionary file does not contain inverted index the program will make own one and will save it in a new file (appending ".ii" to the name). The main idea behind the inverted indexes is to use the dictionary in both directions - e.g. if it is 'de_en' (German to English), you can browse it as 'en_de'. This make sense if the dictionary has been created in 'word list' style. If the clues are big paragraphs, the sense of inverted indexes is under question.
'Show Status Bar' if unchecked, will remove the the bar for the additional messages.
'Show Transliteration Bar' - this check box shows and hides an additional bar containing a text field, a button, and a combo box. You can select a transliteration operation from the combo box and when the button is pressed, the text in the field will be transliterated. The behavior of the controls depends on all settings you have done in the other dialogs. For more detailed description see the documentation of CPT Word Lists.
'Wrap Lines' if not set, the program will show any
clue/tag in one line even if it is hundreds of characters.
Notes: There is no CPT support for 'special' languages
like Thai. If the clues are in RTL script stored in visual order (usual
case for Hebrew), and you select 'Right Alignment',
the program will use the logical order for the wrapping
(with all consequences of the double conversion),
otherwise, it will be wrapped as LTR script.
'No Empty Lines' if set, will disable the separation of clues with empty lines.
'Right Alignment' should be set for right-to-left (RTL) scripts.
'Shaping' should be set if you need Arabic shaping or if the dictionary is in 'Thai Composed' form, or if the font does not support properly the combining marks.
Use this tab to select the text of the tags to be shown.
'Morphology/Topic/User/Clues' serve the separate built-in tag groups.
Some tag display texts are quite boring and you could
switch them off.
'Show Repeated Tags' if not set, will remove the sequentially
repeated tags.
'Tag Names' means "show display names of tags".
'Tag Codes' means
"show the codes of tags".
This tab shows and allows to select any of the tags included
in the dictionary as filters for the words and clues.
The tags are presented by the codes and the display text
(as created by CPT Word Lists).
Since there are 4 groups of tags ('Morpho', 'User', 'Topic',
and 'Clues'), the filtering is done in two steps:
the first is in a group of tags and the second is in total
(for all groups).
In a group: if a tag is not selected, the word/clue having
this tag will be marked as 'bad'.
In total: if a word/clue has at least one 'bad' mark, it will be
excluded from the search/browse list.
In simple words, you can do global queries via the tag filters. For example, open the 'smile.dic' dictionary. In the dialog 'Display Options' select 'Browse Style' and 'Words' in 'Style' tab, and the tag 'miniatures' only from 'Morphology Tags' in 'Filters' tab, and you will get the words of one or two characters only in the display list.
'Select All' button can be used to select all items in the current list. 'Ignore Unselected npt/bpt' is used when the list contains npt type and bpt type tags. If you need to select tags, let's say, from bpt group only, you can check the box and this will mean "ignore the unselected from the other group". If not checked the filter will skip the words having unselected tag from npt group even if it has the selected bpt tags.
'Select From List' will enable the list box and you can
select exactly the lengths you wish.
Just to remind that you can do multiple selection via the mouse
and Ctrl key pressed.
'All' means no length filters.
The rest of radio buttons from
'<7' to '>=33' can be used
to select a range of lengths.
| 4. Search Text Field |
This is the field in the center of the top window bar. Here you can enter a word to search for. Simple regular expressions, bidi, and Unicode notation are supported (if not disabled). Note that the searching is for words, not strings. For example, in 'Search Clues' mode, to find an entry containing "word", you have to enter the regular expression "*word*", or in 'Search Words' mode, to find the word "word" the pattern "word" is OK. To switch off the regular expressions, use the 'Input' tab in 'Search Options' dialog.
The search pattern you can enter is restricted to subset of regular
expression syntax using the following special symbols:
| * | matches 0 or more characters |
| ? | matches exactly one character |
| | | starts alternative pattern to search |
| \char | is the 'escape' way to match the char, where char is any Unicode character |
| [set] | matches any one character from the set |
| [^set] | matches any one character not in the set, where set can have the following forms: |
| charString | includes the characters from the string |
| char1-char2 | includes the characters from char1 to char2 in the ascending Unicode order |
Since the idea is to match words, not strings,
the meaning of '*' and '?' is the same as used in operating systems
for the file name expansion, but different from the classic regular expressions
used in egrep and friends. Here are two examples:
ase[^ex]*
will match all words having 4 or more letters, starting with 'ase'
but not including 'e' and 'x' as a forth character;
ba??a|ga????
will match all 5 letters words, starting with 'ba' and ending
with 'a', and will match all 6 letters words, starting with 'ga'.
The syntax of the search pattern is checked and you could receive error message even for well-formed expression due to restrictions in the implementation (e.g. protected CTrees).
Meanwhile, you can see the whole dictionary in the text area via selecting 'Search Style' and 'Words' in the 'Display Options' dialog and then enter the search pattern "*". Well, there is no problem for small dictionaries, but all depends on the available memory - the program has to unpack everything and to format the lines in the text area. If the dictionary is protected some how, this kind of search will be ignored or you will not be able to copy from the text area via the clipboard.
You can use the 'Search' button instead of Enter key to start the searching. This button will mean 'Find Next' when working in 'Browse Style' - the searching will start from the list item following the last selected. The Enter key will always start from the beginning.
| 5. Search Options |
The first button on the right of the text field will start a dialog for the keyboard input and search options.
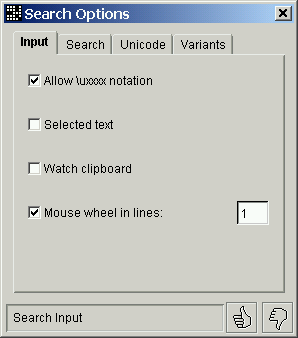
'Allow \uxxxx notation' will transparently convert the \uxxxx encoded characters to Unicode.
MS Windows Version:
'Selected text' is to grab a search pattern from other window. In this mode you have to select a text from a window and move the mouse pointer (no dragging, no clicking) into the text field of CPT Dictionary program. If the text is taken, it will be searched, otherwise, the '?' character will be shown.
'Watch clipboard' is for watching the changes in the system clipboard. Any new text will be immediately searched. You can minimize the program and the result of the searching ('Yes' or 'No') will appear for a while in the desktop bar field of the minimized program.
'Mouse wheel in lines:' is to convert the mouse wheel
rotations to Up and Down arrow keyboard keys.
The program code is implemented in C and you can use
the mouse wheel with any Java VM version.
Note: The check box and the text field will be shown if you have
a mouse with wheel.
Linux Version:
'Keyboard converter' when set, the selected encoding from 'Select Font' dialog will be used to convert the typed 8-bit characters to Unicode. For example, under KDE and Xkb on, if you want to use cp1251 for Cyrillic, you have to select the converter koi8-r (don't be confused that KDE3 is showing properly in all qt3 based applications the Cyrillic letters - it knows that the broken standard Xkb files by 'Cyrillic' mean only koi8-r, KDE 2 and 1 are not that smart and will show nothing..., of course, if you use a proper Xmodmap file or Xkb on with the right files, the converter encoding should be cp1251 in KDE, GNOME, etc.).
'Clipboard converter' will be shown/available only if the Java VM is 1.3.1 and above. If you exchange data with applications supporting properly UTF8_STRING or COMPOUND_TEXT (all Java, KDE3 applications, Mozilla, etc.) you should switch off this flag. If switched on, the behavior is the same as for the keyboard converter. The converter will be used in 'Selected text' and 'Watch clipboard' modes as well.
'Selected text' is to grab a search pattern from other window via the ICCCM 'PRIMARY selection' convention. In this mode you have to select a text from a window and move the mouse pointer (no dragging, no clicking) into the text field of CPT Dictionary program. If the text is taken, it will be searched, otherwise, the '?' character will be shown. The program code is implemented in C and this is the only mechanism for taking foreign data when your Java VM is less than 1.3.1.
'Watch clipboard' starts a separate thread for watching the changes in the 'system clipboard' (ICCCM 'CLIPBOARD selection'). This mode is not available for Java VM less than 1.3.1. Any new text will be immediately searched. You can minimize the program and the result of the searching ('Yes' or 'No') will appear for a while in the desktop bar field of the minimized program.
'Emulate mouse wheel' is to convert the mouse wheel rotations to Up and Down arrow keyboard keys. Again, the program code is implemented in C and you can use the mouse wheel with any Java VM version.
'Regular expressions' will switch on this processing.
'Ignore case' will switch on the case-less searching.
'Special casing' will switch on the special Unicode casing when changing the letter case.
'Stop on first match' is valid for 'Search Style' mode.
'Additional Dictionaries' is to open all dictionary files from the additional list and to search there as well.
'Unicode Normalization' means to apply the selected normalization to the source text and to the search pattern. Use the radio buttons to select the desired Unicode normalization.
The idea is to transform the text into one of the composed or decomposed forms, unifying Unicode characters for easier comparing of words. The standard forms are described in Unicode Technical Report #15. Here is a very brief summary.
In Unicode some "conceptual" characters or graphemes can be represented in two or more ways. The composition forms are "shrinking" the letter representation and the decomposition forms are "expanding" it. There are canonical and compatibility modes. Let's explain with an example: angstrom-sign (\u212b), A-ring (\u00c5), and A + ring (A + \u030a) are three variants of one letter glyph. The normalization of this letter is done as follows: If the input is angstrom-sign, A-ring, or A + ring: for canonical decomposition, the normalized form will be A + ring; for canonical composition, the normalized form will be A-ring.
The next example is with compatible forms. The Latin 'ffi' ligature has been used in many texts and there is single Unicode character ffi-ligature(\ufb03). In the new texts the people are using 'ffi' string and here comes the compatibility mode.
If the input is 'ffi' string:
for canonical/compatible decomposition/composition,
the normalized form will be 'ffi' string.
If the input is ffi-ligature:
for canonical decomposition/composition, the normalized
form will be ffi-ligature;
for compatible decomposition/composition the normalized
form will be 'ffi' string;
The list of radio buttons contains the standard forms from Unicode Technical Report #15:
To switch to the combinatorial ('Variants') mode, the check box 'Search Variants of Words' should be set.

The radio button 'Palindromes' means to search words, which read the same forward and backward and are symmetrical (e.g. "malayalam").
The radio button 'Reversions' means to search words, which when are read backward are the same as the search pattern and not need to be symmetrical (e.g. "doom" and "mood"). The palindromes are subset of this class and if the search pattern is palindrome itself, it will appear in the result list as well.
The radio button 'Anagrams' means to search for all words, which have the same characters as the search pattern (e.g. "acre", "care", "race").
The radio button 'Similar' means to search for all words, which have 'almost' the same characters as the search pattern. The minimal percent for the matching can be given in the text field on the right (as integer between 1 and 99). This is the slowest search from the Variants group.
The check box 'Ignore Spaces' will slow down the process, but will allow to find palindromes like "pull up" or anagrams like "backset" and "set back".
Notes:
The searching of variants is supported in 'Browse Style' mode (the words are searched in the current display list). You don't need to enter a search pattern. Just click on 'Find Next' and all following words from the list will be tried as a search pattern until a variant is found. If you have entered a regular expression, the next match from the list will be the search pattern. For example, to find palindromes starting with "re", enter the pattern "re*". To find all variants in the dictionary, click sequentially on the 'Find Next' button. The searching of anagrams is not supported if 'Unicode Normalization' is set and in 'Browse Clues' mode (you will see an error message).
| 6. Select Font/Locale |
The 'a' button will start this dialog.
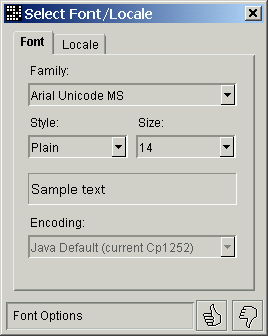
Here you can select the display font characteristics.
For Sun's Java 1.1 the font list is limited to
several fonts. For any other JVM the list will contain
most of the installed fonts on your OS.
Some of the problems with Java 1.1 fonts
could be solved if you set the 'Encoding' to 'Unicode'.
Note that for Linux, the selected encoding will be used
by the keyboard/clipboard converters when
set in the 'Input' tab from the 'Search Options' dialog.
You can type or paste in the local text field any sample text to see how it will be shown using the selected font.
If the dictionary contains IPA8 encoded clues, you should select a font supporting the Unicode IPA block (like "Arial Unicode MS" or "Lucida Sans Unicode").
If in 'locale' directory there is a file, which contains the program messages in your language, it will be shown in the list and you can select it. The program uses a simple algorithm to check if the messages will be displayed properly by your OS and Java VM. The result appears under the 'OK?' field. If it is 'No', you can tell the program to skip this check via 'Force the setting' flag.
When you close the dialog via the 'OK' button, the selected locale messages will be used. The window titles, as a rule, in most cases are in English.
If you want the program to talk to you in your language, you have to add the proper file in the 'locale' directory. Note that there is 'Readme.txt' file with instructions.
| 7. Quit |
Finally, to stop the program, click on the right most button. The current setting for the dictionaries from the list will be saved (if the current user has access to the installation directory).