Stories or narratives are interesting special cases for information retrieval because they don't explicitly say what they are about. Rhetorical devices used in literature (metaphor, metonymy, irony) rely on indirection and not saying things explicitly. Let's say you want to search for all descriptions of characters, you can't just search on the strings "character" and "description" like you would for an ordinary subject in an internet search engine. If you want to locate character descriptions you have to use a whole set of strings, phrases used to describe physique, clothing, and the emotional life of characters. You want to look for passages in the text where there is a high density of these strings. Here we look for paragraphs with a high density of topical phrases or strings. This works for authors like Balzac who use long paragraphs for detailed descriptions. It doesn't work as well for other authors such as Dickens where some other measure of topical density not tied to the paragraph would be better.
[Topical Paragraph Extractor| Text Search Machine (DFA) Constructor| Searching for Multiple Sub-Strings]This program extracts paragraphs out of a set of Project Gutenberg plain text files that have over a threshhold number of keywords in them. So if your looking for descriptions of characters in Balzac novels like I was then you use a list of keywords describing the physique and clothing of characters.
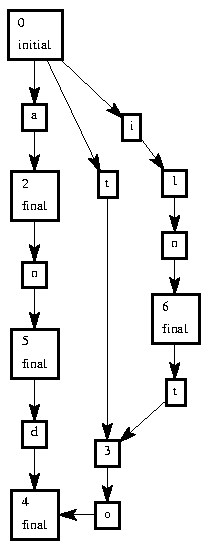
Creates a deterministic finite state acceptor (DFA) from a list of words that when run against a text will identify the words in the text, can be used as a stoplist to eliminate frequently occuring words from a text before indexing it, or it can be used to note the presence of certain keywords in a text, which is the application I'm making of it, to find character describing paragraphs in the writings of Balzac.
The Perl prototype which took about two hours to code will be used to write a C++/STL version, that can be used with various glue/scripting languages like Python, Perl, Tcl/Tk, Visual Basic, Common Lisp. This is my basic strategy, to use these languages as glue languages as set forth in Ousterhout's "Scripting for the 21st Century" and render the more essential algorithms in a language that can be used by any one of them, C++ being the most obvious common denominator.