

New advances in Neuro -Visual Simulation and Symbolic extraction for Real World Computing,
3D Image Analysis and 3D object Digitization
P. Leray
France TELECOM/CNET/DIH
CCETT Centre Commun d'Etude de Telediffusion et Telecommunication
Rue du Clos Courtel, BP 59 - 35510 CESSON-SEVIGNE
(FRANCE TELECOM Research Center)
Abstract:
3D image analysis and automatic modelling using Neurofocalisation
and attractiveness with hardware filters.
Towards a new kind of filter-based data structures instead of splines/polygons.
Abstract:
_________
At present the rendering tasks are made easer thanks
to the numerous 3D graphics cards available on the marketplace. But automatic
digitizing for 3D objects is the key challenge for todays 3D computer graphics.
The goal of this paper is to present research avenues towards direct 3D
digitizing with multi-views cameras, in order to design 3D objects as simply
as 2D scanning.
Recent advances in low level vision analysis gave interesting results related
to Automatic neurofocalisation, and perceptive grouping, mainly thanks
to Professor Burnod researches and his team in the field of Neuro
Visual hardware models.
These techniques are based on multiscale hypercomplex filters such as Gaussian, Laplacian derivatives, and are able to automatically compute highly informative points or zones such as: vertices, vectors, lips, eyes, mouth etc...on natural scenes. These informations can be the basis of keypoints for spline control points.These image analysis tools are giving Neurofocalisation output informations.
They simulate the low level attractiveness of the Neuro-Visual system in the brain: Neurons can be considered functionnally as hardware filters, as they perform sum of products.
Neuro-visual simulations demonstrate for example that neuron ouputs are giving directly matrix transform coefficients, and edge transition in the brain.
It would be envisageable to consider a new kind of filter-based data structures instead of splines/polygons. Such data base could facilitate the gap between 3D objetcs and image processing elements. (The terms used in MPEG4/SNHC is VOP for video object planes: It’s the first time that an image element other than contour, edge, etc, is considered as an object.
Some demonstrations and hardware simulations will be presented.
Moreover, these results can be implemented in hardware. The cortical column as defined by Professor Burnod is a set of complex filters which can be simulated and integrated as well as classic digital filters.
Such informations can be used as inputs for new modelling systems which could design 3D objects without interactive graphical interface via software modellers. At present, only interactive US commercial products are available. These products need an operator who must interactively input in the system vertices and polygon positions. These tasks are very long and boring, thus already a little bit easier than traditionnal modelling systems which need a complete construction with mathematical shapes, or adaptive meshing.
The real take-off for 3D graphics will begin when 3D digitizing will be as simple as a camera or scanner. Such techniques could enhance classical input design for a large sets of objects.
Moreover, it would be possible to define new data structures based on generalized multiscale filters more than splines/polygons.
A new direct bridge could be created between image analysis and synthesis, and for mixing hybrid scenes. (as in MPEG4-SNHC goals).
Recent simulation models of the Neural Visual Cortex in the brain have been developped for merging 3D image & object analysis with 3D Synthesis for ultra-high image compression (MPEG4) and analysis research environment.
Keywords: Neural Networks, 3D Image Analysis & Synthesis, Visual Systems, Simulation, Compression, Functionnalities, MPEG4;
- Automatic focusing process on keypoint, as in the human visual system, allowing new methods
- Multi-level, multi column cooperation for perceptuel grouping, allowing very accurate segmentation. (5 times better than other techniques).
- Possibility of automatic symbolisation, as a tool for bridging the gap between 3D analysis and synthesis thanks to the Cortical Transform.
Significant results have also been achieved in :
- very low bit rate Coding (at 30 Kbits/s and less), with more acceptable aspects which fits with visual System requirements. Moreover, neural tools seem to be generic and well adapted to thevarious input styles of TV sequences, thanks to their learning capabilities & architecture dedicated to all kinds of 2D & 3D Analysis-Synthesis processing.
- Automatic detection and tracking of informative key-points on 3D objects, allowing new advances in 3D recognition.
- Neuro-perceptive grouping, which merge information for a better 2D segmentation.
- 2D and 3D object extraction.
(see references 8 to 10)
INTRODUCTION:
Image synthesis is mainly based on shape representations using splines, nurbs, etc... at the upper level, and polygons at the lower level, for accelerating hardware computations, which are difficult for general complex curves.
Images analysis tools are mainly based on:
- Multi-level filtering process, using several algorithms such as sub-bands, wavelets,...
- Segmentation rules
- Motion estimation based on various block matching techniques.
This two kinds of representation and tools are very far from each other. But in the brain, we are storing obviously shapes and object representations, which can be manipulated as well as with image synthesis techniques, but these shapes are stored in the brain thanks to 2D & 3D analysis technques.
The main process of the brain is the research of semantic abstraction, based on stored difference research.
This task is performed by a set of specialized cortical areas, such as MT, VT, ..., which separate different features for semantic extraction. A computational model of these areas has been defined and implemented in a software simulator by Professor Burnod in 1987 and his team in 1987.
This model is based on the biological concept of the cortical column paradigm in the visual area. The simulator extracts 2D & 3D objects (1) and movements by using the properties of hypercolumns (2) within the visual cortex, for spatio-temporal pyramidal filtering, learning, and performs inter and intra-cooperation between these simulated hypercolumns.
The simulation process has 4 abstraction levels for Analysis and Synthesis: Pixels, Zones, Objects and Labels. Final Synthesis (or reconstruction) is processed by reverse filtering, using non-orthogonal basis filters. Substantial upgrades in terms of compression ratio have been estimated using this algorithm as a whole, or partially, with integrated VLSI.
Current synthesis techniques are currently using shape representations, such as polygons, cylinders, splines, and so on. In the brain, we don't use such kind of representation, but a multiple pyramidal set of filters, processed by elementary neurons: basically, each neuron equals a filter, equals a convolution, equals a rule (as defined in I.A. techniques). The weights (coefficients) each neuron is using are the basis function of the filter; We can interpret the neural function in such term as:
Is the basis function Fn I apply fits or not with the pattern vector Iv I receive in my synapses in input ?
Which is performed by:
Output = Sigmoid Function (SIGMA (Fn*Iv))
The neuron fires if the Output energy is high, and remains unactivated otherwise. At present new generic tools can be derived from human vision, image synthesis, artificial intelligence and neural nets. Each technique has advantages and limitations and they have to be combined in order to get better performance and genericity. It is also interesting to note that efficient architecture is often close to the structure of the visual system associating complementary processes, such as scanning and focusing on points of interest, separation between a What and a Where pathway behind a natural scene, learning from examples, etc.. etc .. Recent neurobiological researches are leading us to new computational models of the human visual system. The cortical model has been presented several times, mainly in the SPIE/IS&T conferences in San Jose (CA, USA: see references).
This models is based on the cortical visual areas architecture and can be used for image analysis, synthesis and compression with 3 main advantages:
2.1. The Human Visual System : a model and a goal for artificial vision:
The biological Visual system provides a general framework with outstanding results, largely better than our best artificial systems: It first enables us to interpret the effect of existing tools (image processing, neural nets) in relation with human visual processing : it is then possible to see how these tools can be combined to analyse pictures that will be perceptably acceptable and can fit with customer requirements.
2.2. Combined Analysis and Synthesis:
CCETT has developped an important background in the field of 3D Image Synthesis, and designed in 1985 a 3D real time Image Synthesis System, which was called CUBI 7, dedicated to broadcast Production, CAD-CAM and Simulation. This machine has been industrialized in Europe, largely leading before SGI machines in 1985-86, and a European Project including Tübingen and Sussex University partnership issued a 3D graphics PC card and a 3D chip, which has now similar performance as the best PC cards in the US.
At present, the great challenge in Computer Graphics is no longer the rendering process, but the 3D input process. Several techniques are now currently used:
- 3D modelling systems
- 3D Lasers
- Multi-views analysis systems
The third ones seem to be very promising, but they need always manual interactive operations which are quite painfull for an operator. 3D Virtual reality will really emerge only when automated 3D digitizing tools will be commercially available.
In the other hand, Neural models of the Visual Cortex provide new tools for image analysis and synthesis, and more generally for scene and movement understanding; We have developped an Analysis-Synthesis system, based on the same filtering process for the feedforward process (Analysis in input) and synthesis process ( for the output).
2.3. Hierarchy of Semantic Levels:
Many image analysis systems operate at the pixel level, where the information data flow is huge.
Classical neural nets associate only a large set of elementary neuron, with the same repetitive architecture: The result is poor traning capacities.
On the contrary, the brain has a specialized, adapted architecture, which separates the visual process in elementary tasks, leading to less datas, but from higher level.
->good for compression, and scene understanding/digitizing.
Since the different types of low and high level visual processes are performed in the brain by the same type of neuronal circuit, the cortical column, we can propose principles for hardware architectures associating extraction capacities of image processing tools and learning capacities of neural nets; furthermore such architecture could perform in parallel at different rates the main tasks unresolved by our computers:
- Object shape identification.
- Object movement
- 3D digitizing
- Compression with different levels of analysis
- Synthesis (Rendering).
3. Basic Modeling principles of the human visual system: a cortical architecture:
All cortical areas have a similar neural architecture, they use similar neural codes, they effect the same types of neural operations and learning processes. At lower levels, as in the primary visual cortex, such a neural operation corresponds to spatial or spatiotemporal filters, such as the well known Gabor filters, which allows the extraction of specific features in the image from the pixel content. At higher levels, similar neural operators can learn to recognize the structure and characteristics of objects: this ability is due to the flexible connection weights between neurons, which shape their activation, and the appropriate recognition is learnt from examples and the stored information is distributed on a large number of neurons.
The main feature of the cortical architecture is the association of these neuronal operators in specialized subsets and circuits: they cooperate locally to extract the "useful", "interesting" or "important" information in the image.
Firstly, they are grouped in circuits called "columns" ; neuronal operators in a column extract a common information from different sources : from external sources on the feedforward connections (for ex. spatio temporal filtering on the image), from the control by higher levels on the feedback connections (expectations, hypothesis, goals), from neighbour information on lateral connections (perceptual grouping). Modeling properties of such circuits allow us to solve problems of fusion between different sources of information and problems of cooperation between processes.
Secondly, columns are grouped into "hypercolumns" which extract a set of complementary informations : for example in the primary visual areas, extraction in each part of the image of different orientations, each part of the curvature, of the movement directions, of the stereo information, of the color, etc..; furthermore , these hypercolumns perform a multi-scale analysis of the image. The "population activity" of the neuronal operators in an hypercolumn gives two complementary informations: what is the information content of the image (for coding and synthesis, as coefficients of a fourier transform) , and what is its importance (for selection).
Visual processing is performed by a set of cortical areas forming the visual system. All these areas are connected together in 3 main pathways with a functional specialization:
- the pathway formed by the areas in the temporal lobe tells us What the object is which is put on the center of the retina (or Who is the person) ?
- the pathway formed by areas in the dorsal parietal lobe tells us Where the different object and person are in a scene?
- the intermediate pathway extracts information from movements: how objects and people are moving in the scene ?
These 3 pathways can be decomposed into four processing steps corresponding to increasing semantic abstraction levels:
3.1. Level: Pixels
The first step processes pixels : neuronal operators provide a set of complementary filters which extract specific features from the image: oriented and contrasted lines, end of lines, oriented movements, color contrast..
3.2. Level: Zones:
The second step processes 2D1/2 zones: neuronal operators extract characteristics of local surfaces as homogeneous zones of pixels : extension, orientation of the surface in 3D space, colours and textures.
3.3. Leval: Objects
The third step processes objects in a viewer-dependent reference axis: neural operators form clusters which code the main different aspects and views of a 3D object (in observer centered coordinates).
At levels 3.2/ , 3.3/ and higher, zone and object definitions are largely more complex and more flexible than those used by classic image synthesis tools: Homogenous Zones and 2D or 3D Objets can be considered as perceptively homogeneous properties : for example we consider a tree as an object, even if the wind involves complex geometric transforms in the leaves: Our learning in the brain has not only recorded the shape of a branch, but has been learning also the movements of the tree. We are far beyond a classic 3D database with splines...
3.4. Level: Labels:
The fourth step processes viewer-independant prototypes and labels: independent in size, orientation, and position of the retinal image. They also store the relations between prototypes (as semantic graphs).
This is the reason why we can introduce now the FILTER REPRESENTATION instead of the SHAPE REPRESENTATION classically used by image Synthesis techniques.
These 4 step levels cooperate through feedforward connections to perform the analysis of the image, from pixels to labels, and through feedback connections to perform a "synthesis" of the image, from labels to pixels.
All steps participate in the visual perception to tell us what is important in the image. For example, the first step can guide the center of gaze to the regions of the image with a rich low-level information content, as defined by the population activity (associating contrast, curvature, movement, etc..) . It is worthwhile to note that eyes, faces, hands, silhouettes, are very rich in such low level information. The higher steps guide the gaze direction and focus of attention on the recognized objects and persons in the scene. Learning concerns all levels, but with a general-to-specific gradient: : learning in lower levels stabilizes the family of spatio-temporal filters which are quite general and predictible, independent of each individual experience. They seem sufficient to be able to recognize large categories such as object vs person. Learning in higher levels is linked more to experience, culture and specific interests.
4. Cortical Analysis: Feature extraction
4.1. Adaptive level of Analysis:
Extraction of information at different levels is directly useful for different analysis levels of :
- answering questions on what is in the image, where and how it moves allows us to make predictions on the next images ; several levels of prediction are possible depending upon the intensity of neuronal responses at the level of pixels, zones, objects or labels.
- neuronal population activities allows us to quantify the perceptive importance of information at each level: such quantification is necessary in order for us to be able to know where the quality of information should be best preserved: although at higher levels perceptual importance depends most on individuals, with their culture and history, at lower levels it is quite universal : importance of eyes, mouth, movements and face expresson, moving objects vs background, etc...
Such multi-level extractions (1) can both be compared with existing techniques of prediction and quantification, but also provide new tools to enable us to go further into compression ratio while keeping better qualities in images:
At the pixel level, neural operators perform extractions similar to waveform-based coding(such as wavelets or Gabor filters); but cortical modeling allows us to determine a redundant set of extractors (contour, curvature, etc) with non linear interactions which give supplementary information:
- where are the zones of interest most likely to be focused at that should be transmitted with the highest precision?
- what is the grouping of information in zones homogeneous with their movements, and which of their textures is the most perceptively acceptable?
At the zone level, neural operators can be compared with object oriented coding which uses general models as planes or smooth surfaces for object models . Information, such as surface orientation and motion information is estimated from image sequences and is used for motion compensation or motion interpolation. In the cortical model, interesting tools can be derived for fusion of different algorithms extracting such a surface and movement information, for perceptual grouping to define homogeneous zones, and for fuzzy description of surfaces of objects allowing more natural aspects in a synthesized image.
At the object level, neuronal operators are quite similar to 3D model based coding which uses detailed parameterized object models ( for example, parameterized 3D models with control points of a person's face). Obtaining such a detailed model is difficult, since it requires a description of an object in terms of structure and characteristics (what is the appropriate graph?). In the cortical model, higher levels are neural nets which can learn these characteristics from examples, on the basis of the extraction and selection performed by lower levels.
4.2. Low level attractiveness:
In the human visual system, neural population activity in the primary visual area controls gaze direction via the superior collicculus: this population activity can be viewed as a quantitative index of the low-level attractiveness of gaze direction in regions of the image. It is thus important to transmit the more attractive zones (the "attention points")with higher definition and quality.
The cortical model provides a tool to estimate the "low level attractiveness" and to establish a hierachy of the "points of interest" in the image where spatial and temporal variations are the "richest for perception". The basic hypothesis is that a zone is "perceptively rich" because neural population activity in this zone is strongest.
This model tested on natural images shows a high degree of attractiveness on eyes, faces, moving outline, etc. When the compression ratio increases, it is therefore important to implement transmission with content-dependent priority of this type in order to keep a good quality perception.
Low-level attractiveness at two filtering scales: 32*32 left, 16*16 right.
Notice that the 4 square vertices (left) have been detected, and also mouse, lips, eyes at different scales. Right, vertices and edges are detected.
4.3. Data fusion and Perceptual Grouping for a better prediction:
Perceptual Grouping:
Modeling the set of low-level cortical operations performed on the optical flow and texture provides new tools for extracting zones in the image which are homogeneous in terms of movement and texture . The main properties of these tools are to solve the data fusion and perceptual grouping problems.
Extraction of homogeneous zones in the brain is not performed by a unique process, but by a set of neural operators which provide complementary predictions. For example, for movement perception, a neural operator on feed-forward connections can perform spatio-temporal filtering, and those on lateral connections can extract correlations in space and time which are consistent with the hypothesis of a moving object. Modeling interactions between these operators give more robust and cleaner results. This model provides a tool for cooperation between algorithm and data fusion which is consistent with psychological processes of perceptual fusion and grouping.
All these feature extractions processed by the feedforward cortical Analysis lead to the definition of a global Analysis/Synthesis system, which can be used for ultra-high image compression
5. THE SYNTHESIS (Reconstruction) PROCESS:
Classic coding schemes are generally using orthogonal basis filter
functions, with fixed coefficients, which are very convenient for a perfect
reconstruction. However, these basis are rigid, image independant, and
in consequence poorly adapted to particular image characteristics. In our
Cortical Transform paradigm, we use the same filter basis functions
for analysis AND synthesis, even if this filter basis is not orthogonal.
In consequence, we can choose filters whose neural activity is strong,
both for analysis and for synthesis: It is obvious that the stronger the
neural activity, the easier the corresponding filter will be adapted.
Let I(x,y) the luminance value be at x,y; Gi(x,y) a set of non orthogonal basis functions, for which each neural activity is ai. We have at scale k:
ak = Si I(x,y)*Gik(x,y)
If the basis functions are orthogonal, we can reconstruct exactly I(x,y) using:
I(x,y) = Sk ak*Gik(x,y)
In our model, functions are not orthogonal, and ak are adjusted using an iterative neural scheme, minimizing the error:
|e |2 = | I(x,y) - S ak*Gik (x,y) |2
Such a process can be generalized at each abstraction level, making it possible for the cooperation between analysis and synthesis. In particular, 3D objects can be digitized using a set of Neuron-Filters, synthesis being performed by such a reverse filtering process.
6. Towards a new cortical multi-level Analysis and Synthesis system: CUBICORT
Using the feature extraction we have described above for image analysis and compression, it is possible to propose an compression-decompression scheme based on this paradigm. This system is composed of two Analysis-Synthesis modules, one for the coder, and the second for the decoder.
6.1. General scheme of a Cortical Analysis-Synthesis system:
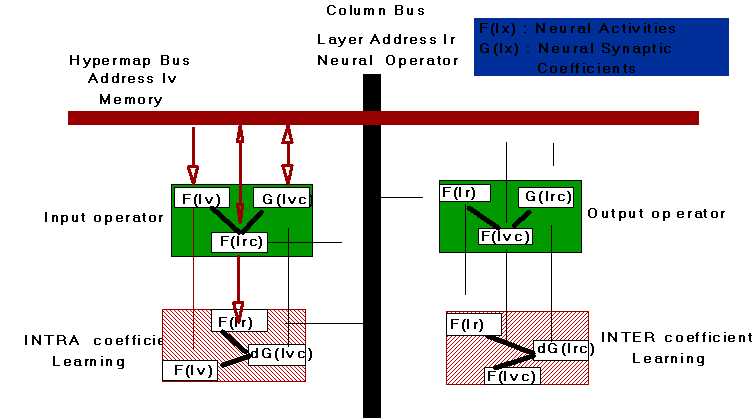
An "Hypermap" is a memory that stores all parameters and results at a given level of processes: it consists of a set of "hyperpixels" adressed by a "pilot index" specific to each level : position in the image at the pixel level, homogeneous zones at the zone level, object as viewed in the scene at the object level, and label at the prototype level.
Information processing is driven by the pilot index and performed by a set of parallel processors , the "hypercolumn", performing a simple neural-like operation is given by activation and learning rules (Sums and products) : parameters (synaptic weights) are dependent on the pilot index only at the higher levels.
Two different levels of processing are implemented in Hypercolumns :
- intra-layer performing a specific neural-like processing on each type of information, with implementation of an activation and a learning rule; for implementation of low-level vision, parameters represent the filter kernels.
- inter-layer: combining different results within each hyperpixel for data fusion and perceptual grouping. It facilitates implementation of different types of neural network learning : for example feedforward can be learned with feedback information.
6.2. Redundant coding representation for analysis:
Coding is redundant. It is given by the results of all the operators in the hypercolumn (hyperpixel) : only higher ativities are taken into account to describe the image (as coeff in DCT transform). Transmission of triplets (pilot index, operator index and values) allows the synthesis of the image since emitter and the receiver have the same operators with the same parameters, acquired through a common learning.
Compression is thus acquired through the selection of information at each level of processing. Each level can be either independent, or associated with extraction at other levels. For example, at the higher level, only the label can be transmitted and the compression ratio can be very high; at lower levels, surface texture, color and orientation allow us to synthetize a view of the object ; at the lowest level, local results of filters give a more natural view of the object.
Analysis could also use such tools for a new kind of "cortical" representation of 3D objects based on the cortical transform. Such representation allows the same manipulation possibilities as synthesis techniques: 3D displacements, illumination models, boolean operation on objects, ... plus learning capabilities, and a direct link between analysis and synthesis.
Moreover, analysis and synthesis can be combined with a generic common data structure.
6.3. First results:
6.3.1 Hyper compression:
Non orthogonal multi-semantic levels basis functions have been investigated: In our last presentation (MPEG 4 Paris) we cut by 2 the transformed entropy;
For still image compression, a compression ratio of 130 to 190 was achieved with better visuel quality than JPEG.( lena: 0.0228 bit/pixels (compression ratio:130 ) Susie: 0.0158 bit/pixel (compression ratio: 190).
At present, we are showing our last results for animated images: Perceptive grouping & attention zones, and more generally feature extraction has been implemented using spatio-temporal filtering. Test sequences have been used - (see video animations at 30 kBits/s) -
6.3.1 Real world computing-Object extraction and manipulation:
Neuro-focusing simulation and symbolisation have demonstrated that it is possible to extract directly object keypoints: for example, our simulator can extract vertices of a cube, even without prior training. These keypoints can be used for inter-images correlation, for digitizing objets and moreover, an efficient texture mapping, which is the key element, (prior to shape precision) for highly realistic images, with less polygon than those obtained by classic modelling techniques..
Major improvements have been demonstrating in the field of: Object morphing, Keying, Adding or substracting 3D objects in a natural scene. (New spectacles on a face, eyes magnification, see demos).
6-4: Hardware implementation:
A schematic drawing is schown here, which has not been yet implemented. It can perform all filtering operations including low level filtering, learning, contour and 2D and 3D object extractions. Such machine could be very usefull for further researches, because computation time is very important. Simulations have been done in France Telecom/CNET.
7. Conclusions:
Using multi-level cortical 3D Image Analysis and Synthesis models, a new research axis is now investigated:
-A new global ultra-high compression scheme, where specific approaches such as 2D and 3D object oriented methods, regions, sub-bands, can be integrated in a learning cooperative multi level process, derived from neuriobiological models. Each feature extraction such as the low level attractiveness, or perceptual grouping and more generally neural feature extraction are new tools giving the hierarchy of importance for each zone in the image. Compression ratios can be multiplied using such means, independently from other compression tools.
Such analysis-synthesis is also flexible, and fits in much more with human requirements, by the use of reverse filtering process, derived from natural brain filters, at each abstraction level that we have described (Zones, Objects, and labels).
- Combined Image Analysis synthesis as a new tool for:
- Significant upgrades for intelligent object digitization
- Mixing natural scenes and synthetic objects.
- New keying tools and Z-Keying tools, without "blue" background.
- 3D objects digitization.
- New kind of Image processing machine:
Our model can be used as a general analysis/synthesis system, with feature extraction for target recognition, segmentation, contour extraction, and information processing.
At the end, neural hardware implementations are much more simple, robust, and cost effective because of their intrinsic redundancy, and self similarity of the main operator: the Cortical columns based on a set of elementary simple Neurons.
7. References:
[1] Burnod, Y. "An Adaptive neural network: the cerebral cortex." Book: 400 pps. Masson; Prentice Hall 1988.
[2] Leray, P. "A 3D Syntheic Imagery Generator in real time" presented at the: Image Generation/display Conference II Af Human Resources Laboratory, Phoenix, AZ pp 78-89 1981.
[3] Leray P. "A 3D animation system Datastructures for Raster Graphics" Data Structures for Raster Graphics Springer-Verlag pp 165 - 171 1985 .
[4] Leray P. "Towards a Z-Buffer and Ray-Tracing Multimode System based on Parallel Architecture and VLSI chips", Advances in Computer Graphics Hardware 1 Springer Verlag pp 141 - 145, 1987.
[5] Leray P. "Modélisation et architecture de machines de synthèse d'image pour la représentation et le rendu d'objets tri-dimensionnels sur écrans graphiques à balayage." University of Paris II , Doctorate 1990.
[8] Leray P. Y. Burnod "CUBICORT: A simulation of a multicolumn
model for 3D Image Analysis, understanding & compression for Digital
TV, HDTV & Multimedia" 1993- Laurence Erlbaum Associates, Publishers
- Hillsdale, New Jersey
IWANNT: International Workshop on Applications of Neural Networks to Telecommunications
Race Project MAVT Seminar: Rennes - France 94.