A Jáva környezet terjedésében jelentõs szerepet játszhat, hogy a programozók milyen szabványos, minden platformon implementált könyvtárakat használhatnak. Már a JDK kezdeti változata is tartalmaz néhány jól használható könyvtárat, mint pl. a hálózatkezelés (java.net), programkák (java.applet) vagy a kezelõi felületek (java.awt) támogatása. Azonban komoly üzleti programok írásához óhatatlanul az adatbázis-kezelés támogatására is szükség van.
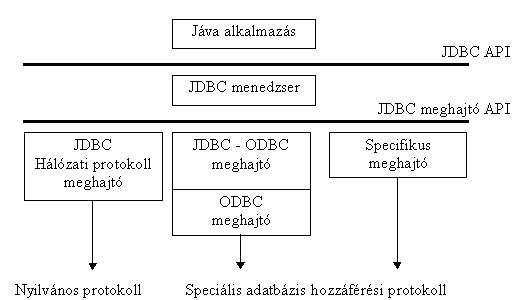
Az adatbázisok kezelésére szolgáló JDBC (Java Database Connection) könyvtár bekerül az év végén megjelenõ JDK 1.1-es változatába, azaz alap-könyvtárrá válik, azaz a programozók minden architektúrán számíthatnak a könyvtár meglétére. A JDBC érdekes, és remélhetõleg gyakran követésre találó módon született. A korai specifikációt közzétették az Internet-en és azt a befutott megjegyzéseket figyelembe véve, csak többszörös módosítás után véglegesítették. Azóta a JavaSoft a specifikációnak eleget tevõ implementációt is közzétett, sõt nagy tempóban dolgoznak a független implementációkat tesztelõ készleten is.
Bár a JDBC módszerei segítségével tetszõleges SQL utasításokat, sõt bármilyen szöveges parancsot el lehet juttatni az adatbázis-kezelõnek, de a fejlesztés alatt álló teszt készlet megköveteli, hogy az adatbázis legalább az ANSI SQL92 alapszintû (Entry Level) specifikációját támogassa. Amennyiben az adatbázis-kezelõ megengedi, lehetõség van az adatbázis-kezelõn tárolt eljárások hívására is.
A meghajtók implementálására több mód kínálkozik. Készülhet olyan meghajtó, amely valamilyen gyártó specifikus módon kommunikál az adatbázis-kezelõvel. Másik módszer, hogy egy már meglévõ, szabványos ODBC meghajtót megfejelnek egy vékony réteggel, amely a kívánt specifikációra konvertálja az ODBC felületet. Lehetõség kínálkozik arra is, hogy valamilyen nyilvános, általános protokollon keresztül kapcsolódjunk egy adatbázis-kezelõhöz. E két utóbbi megoldás elõnye, hogy több gyártó adatbázisát is ugyanazon meghajtó szolgálhatja ki, igaz viszont, hogy általában kissé lassabban, mintha specifikus meghajtót használnánk.
Ezeken a megszorításokon csak a "megbízható" - digitálisan aláírt - programkákkal lehet majd túllépni, no meg az ún. háromlépcsõs (three tiers) kliens-szerver rendszerekkel, ahol a programka a közbülsõ szerverrel tartja a kapcsolatot, amelyik az adatbázis igényeket szétosztja esetleg több gépen elszórt szerverek között.
Megjegyzendõ, hogy a JDBC nem foglalkozik az ügyfél program és az adatbázis-kezelõ közötti adatátvitel titkosításával, ez a meghajtó feladata, felelõssége.
Az alprotokoll neve a meghajtók kiválasztásánál játszhat szerepet, hiszen a JDBC egyes kapcsolatokhoz más-más meghajtót használhat. Az adatbázis hivatkozás pedig már meghajtó specifikus szöveg lehet, bár az ajánlások szerint ahol lehet, használjuk a szokásos URL szintaxist. Például a
egy ODBC feletti meghajtó használatát írja elõ az employee adatbázishoz, kiegészítõ paraméterként megadva a felhasználó nevét és jelszavát, míg a
a vala.hol.com gép 2100-as kapuját használva a records adatbázisra hivatkozik, az általános hálózati protokollt használó meghajtón keresztül.
import java.io.*;
import java.sql.*;
class Select
{
public static void main(String argv[])
{
try
{
Connection conn
= DriverManager.getConnection("jdbc:odbc:employees");
Megnyitunk egy kapcsolatot az ODBC protokoll segítségével
az employees adatbázishoz.
PreparedStatement stmt = con.prepareStatement( "SELECT emp.empno, emp.ename, dept.dname " + "FROM emp, dept" + "WHERE emp.deptno = dept.deptno" + " AND dept.loc = ? ");A nyitott kapcsolathoz hozzárendelünk egy ún. elõkészített parancsot. A parancs tartalmazza az SQL SELECT utasítást, amely az eredmény oszlopait elõállítja.
stmt.setString(1, argv[0]);Az SQL parancsban kérdõjel jelzi a megadandó paraméter helyét, ezt a setString módszerrel definiáljuk.
ResultSet rs = stmt.executeQuery() while (rs.next())A parancsot végrehajtva az eredményekhez egy ResultSet típusú objektumon keresztül férhetünk hozzá. A next() módszer az eredmény tábla következõ sorát készíti elõ. Egy while ciklusban végigfutunk a sorokon.
{
int empno = rs.getInt(1);
String ename = rs.getString(2);
String dname = rs.getString(3);
System.out.print(empno);
System.out.print(ename);
System.out.print(dname);
}
A ciklusban az eredmény aktuális sora egyes oszlopainak értékéhez
a getXXX módszerek segítségével férhetünk
hozzá, ahol az XXX egy Jáva, vagy JDBC adattípus
neve. Az értékeket kiírjuk a szabványos kimenetre.
}
catch (java.lang.Exception ex) { ex.printStackTrace(); }
A példaprogram elég lezseren kezeli a futás közben
esetleg elõforduló kivételeket, minden lehetséges
kivételt egy kalap alá véve egyszerûen kiírjuk
az elõforduláskor érvényes hívási
láncot, majd kilépünk. Egy "tisztességes" programban
ennél szelektívebben illene a kivételekkel bánnunk.
finally
{
stmt.close(); con.close();
}
Az összes sor kiírása, vagy egy hiba bekövetkezése
után lezárhatjuk az utasítást és mivel
a programban más parancsot nem akarunk végrehajtani, lezárjuk
az adatbázis kapcsolatot is.
} }Ennyi az egész. A program persze szándékosan egyszerû, de a legfontosabb lépéseket illusztrálja:
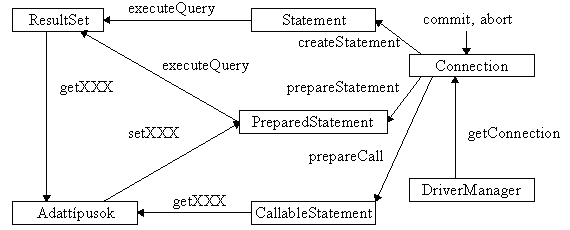
Az itt ábrázolt osztályok segítségével a felhasznált adatbázisok szerkezetének ismeretében a leggyakoribb mûveletek könnyen végrehajthatók, de a JDBC definiál az adatbázisok szerkezetének - például táblái nevének, az oszlopai nevének és típusának -, mûködési paramétereinek megállapítására szolgáló osztályokat is.
| SQL típus | Jáva típus |
| CHAR | String |
| VARCHAR | String |
| LONGVARCHAR | java.io.InputStream |
| NUMERIC | java.sql.Numeric |
| DECIMAL | java.sql.Numeric |
| BIT | boolean |
| TINYINT | byte |
| SMALLINT | short |
| INTEGER | int |
| BIGINT | long |
| REAL | float |
| FLOAT | float |
| DOUBLE | double |
| BINARY | byte[] |
| VARBINARY | byte[] |
| LONGVARBINARY | java.io.InputStream |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
A relációs adatbázis-kezelésen túl a Jáva objektumorientáltsága kínálja az objektumorientált adatbázisok felé nyitást. A már bejelentett objektum sorosítás (object serialization) könyvtár segítségével egyszerû perzisztens objektumokat lehet létrehozni, de készül az ODMG (Object Database Management Group) által specifikált objektumorientált adatbázis-felület Jávához illesztése is.
 Kiss István
Kiss István
updated: 97/05/01, http://www.eunet.hu/infopen/cikkek/java/jdbc.html