There is a great deal of information available on the Internet. However, it can be extremely difficult to locate them, largely because of the huge size and extremely chaotic nature of the Internet.
The situation is aptly summed up by the title of a recent article in Wired Magazine (Steinberg 1996):
SEEK AND YE SHALL FIND (MAYBE)
Finding information on the Internet can be a time consuming and frustrating activity, with no guarantee of success (as indicated by the above title). But there are mechanisms available on the Internet to make this process of resource discovery easier. The most important of these are discussed in this chapter.
Methods of resource discovery on the Internet may be classified under four categories:
- Newsgroups and Mailing Lists
- Search Tools
- Serendipity and Brute Browsing
7.1 Newsgroups and Mailing Lists
Newsgroups and Mailing Lists offer an excellent means of locating and getting in touch with people with specific interests or expertise. These tools can be used in two ways:
- Directly as a means of contacting specific groups of people with the objective of getting feedback or information from them.
- Indirectly as a means of getting pointers to sources of information on specific subjects.
An example of the former use was a "Delphi Study of Issues Relating to Design for Global Markets" which was conducted by the author in the first quarter of 1995. This is described later in this chapter. The methodology used for testing and feedback in the present project is another example of such use and is described in a later chapter.
7.1.1 Newsgroups
Newsgroups and how they work was discussed in detail in Chapter 5 of this document. Newsgroups. Essentially, USENET Newsgroups are on-line communities of shared interests. The subject of these shared interests are extremely diverse and the most difficult task is to identify the right newsgroup for a specific purpose.
Fortunately, there are means available to do this in the form of indexes (some of which are searchable) of newsgroups which can be accessed through the World Wide Web.
Some of these are:
-
DejaNews Research Service
http://www.dejanews.com/forms/dnq.html
Internet Newsgroups at The World Wide Web Consortium
http://www.w3.org/hypertext/DataSources/News/Groups/Overview.html
Liszt of Newsgroups
http://www.liszt.com/cgi-bin/news.cgi
Scholarly E-conferences (Mailing Lists, Newsgroups)
http://www.austin.unimelb.edu.au:800/1s/acad
Care should be taken to ensure that a Newsgroup is appropriate for a specific purpose, both from the point of view of the authenticity of the information that may result as well as from the point of view of avoiding "flaming". The communities on the Internet can be very intolerant and often, inappropriate postings to Newsgroups can result in one receiving hundreds (maybe even thousands) of angry responses from all over the world (referred to as "flaming"). So, it is usually a good idea to first subscribe to a Newsgroup and "lurk" in the background, observing the messages being posted in order to get a clear idea of the people on the Newsgroup and their interests.
7.1.2 Mailing Lists
A mailing list is a community of common interests, similar in some ways to USENET newsgroups. The essential difference is that they rely on Email as a means of delivery of information and messages. The have several advantages over USENET Newsgroups. They deliver messages directly without requiring any special effort on the part of the user (beyond retrieving their Email, and in many situations particularly in the work environment, systems are setup so as not to require any special action on the part of the user). Also Email is more or less ubiquitous on the Internet whereas access to USENET is not. Because of the way USENET News propagates, messages from mailing lists often arrive much faster.
There are several programs that operate mailing lists, the most common of which are LISTSERV, ListProcessor and Majordomo. These operate fairly similarly and in principle are practically identical. They maintain a list of Email addresses of people subscribed to the list and automatically make copies of messages and distribute them to the members of the list.
Source: LaQuey, Tracy. Internet Companion Plus: A Beginner's Start-Up Kit for Global Networking. Reading: Addison-Wesley Publishing Company, 1994.
Figure 7.1 Mailing Lists
There are broadly two kinds of mailing lists- moderated and un-moderated. A moderated list is on in which content is controlled by a moderator who reads each message and ensures that it is appropriate for the list. An un-moderated list is one in which anyone can send a message to the list.
A further sub-classification of un-moderated lists is public and private lists. In a public list, anyone can send a message even if they are not a member of the list. In a private list only members can do so- the mailing list program checks the Email address of the sender and will only forward messages from members.
Subscription to a mailing list is usually very simple and is achieved by sending an Email message to a specific address. Getting off a list too is done similarly. Some mailing lists (usually the moderated ones) require approval from the list manager (the person who runs the list) in order to subscribe.
Subscribers to mailing lists usually have a choice between receiving messages individually or in a digest form. A digest is simply a single message that combines a group of messages. Digest are usually sent out once a day (less or more frequently depending on the volume of messages) and can be particularly advantageous for high volume mailing lists- it is probably more convenient to receive a single message once a day rather that 30 or 40 individual messages!
Like Newsgroups, the subjects of various mailing lists are extremely diverse and the most difficult task is to identify the right mailing list for ones purposes.
Fortunately, there are means available to do this in the form of indexes (some of which are searchable) of mailing lists which can be accessed through the World Wide Web.
Some of these are:
-
Interlinks at Nova Southeastern University
http://www.nova.edu/Inter-Links/cgi-bin/lists
International Federation of Library Associations and Institutions
http://www.nlc-bnc.ca/ifla/I/training/listserv/lists.htm
Liszt of Mailing Lists
http://www.liszt.com/
Mailing List Archive at Indiana University
http://scwww.ucs.indiana.edu/mlarchive
Stephanie da Silva's List of Publicly Accessible Mailing Lists
http://www.neosoft.com/internet/paml/index.html
T I L E . N E T / L I S T S
http://www.tile.net/tile/listserv/index.html
Care should be taken to ensure that a mailing list is appropriate for a specific purpose, both from the point of view of the authenticity of the information that may result as well as from the point of view of avoiding "flaming". The communities on the Internet can be very intolerant and often, inappropriate postings to mailing lists can result in one receiving many angry responses from all over the world (referred to as "flaming"). So, it is usually a good idea to first subscribe to a mailing list and "lurk" in the background, observing the messages being posted in order to get a clear idea of the people on the mailing lists and their interests.
Another way of determining appropriateness is to download a list of names and Email addresses of members. Most mailing lists allow subscribers to get a list of members by sending the appropriate command to the mailing list program. Looking at the domain names of users can often give an idea of the nature of people on the list.
7.1.3 A Delphi Study on Design for Global MarketsThis study was undertaken between January and March 1995. The objectives of the study was to obtain a consensus from a global sample of Industrial Designers on the following:-
- The factors that could, in the future, influence the design of products for global markets.
- The aspects of design methods that could change in the future and the factors that could influence these aspects particularly in the context of design for global markets.
- The disciplines or professions which can provide inputs relevant to forecasting future scenarios of design for global markets.
The technique chosen for this purpose was the Delphi method- a technique which allows a structured anonymous interaction between people who are not physically face to face. Delphi may be characterized as a method for structuring a group communication process so that the process is effective in allowing a group of individuals, as a whole, to deal with a complex problem (Linstone and Turoff 1975). Delphi offers a convenient method of involving persons in geographically remote locations in a group communication process.
The key features of the Delphi method are:
- The format is typically, but not always, a paper and pencil questionnaire. It may be administered by mail, in a personal interview, or at an interactive, on-line computer console. The basic data-collection technique is the structured, formal questionnaire.
- The questionnaire consists of a series of items using similar or different scales, quantitative or qualitative, concerned with the study objectives. The questionnaire is accompanied by a set of instructions, guidelines and/or ground rules.
- The questionnaire is administered to the participants for two or more rounds. Participants respond to scaled objective items. They may or may not respond to open-end verbal requests.
- Each iteration is accompanied by some form of statistical and verbal feedback. The former usually involves a measure of central tendency, some measure of dispersion, or perhaps the entire frequency distribution of responses for each item.
- Iteration with the above types of feedback is continued until convergence of opinion, or "consensus", reaches some point of diminishing returns, as determined by the investigator.
- Participants do not meet or discuss issues face to face and responses are kept anonymous.
Participants were selected from among the subscribers to the Internet mailing list called IDFORUM since this allowed reaching a diverse and geographically distributed sample. This mailing list had 498 members from 39 countries as on January 27, 1995 at 19:35:05 (Source: Response to REVIEW request from LISTSERV@VM1.YORKU.EDU.CA) and includes practicing designers, design educators and design students.
A letter outlining the research area and the objectives of the study was Emailed to all subscribers of IDFORUM. Information on the amount of time that participants in the study would have to spend was also included in this letter.
Although it would have been much easier to do this by routing the messages through IDFORUM itself, it was found necessary to Email messages directly to the potential participants. This made it easier for them to reply besides avoiding inundating all subscribers with responses.
A total of three iterations were carried out. Considerations of ease of response had to be kept in mind while designing the questionnaires. The key aspect was the fact that conventional paper layouts do not work through Email- a neat layout with designated spaces for responses is often received in such a garbled format that filling in responses becomes a nightmare. As a result, the approach taken was to provide a blank line below each item for responses. This allowed participants to respond by simply hitting the reply function of their Email software and using the UP and DOWN arrow keys to navigate to these blank lines and fill in their responses.
The study yielded ratings of the perceived importance of factors that could, in the future, influence the design of products for global markets, aspects of design methods that could change in the future and on the disciplines or professions which can provide inputs relevant to forecasting future scenarios of design for global markets. In addition to the numerical results of the study a number of interesting inferences could be drawn from the responses of and justifications provided by participants.
Besides the above findings, the study also gave insight into the capabilities and limitations of the Internet as a research medium:
- In principle, the Internet has a global reach but that does not always mean that it is possible to get a global sample. In this study, though the IDFORUM mailing list had representation from 39 countries, actual participants were from only 8 countries.
- Participation in the study dropped pretty drastically- although 27 people initially agreed to participate, only about 16 went through the entire process. Also, many participants did not bother to provide the requested justifications for their responses. This is probably in part due to the instantaneous nature of the medium which results in a short attention span.
- While the use of Email for the study did allow quick responses, the same "instant nature" of the medium did seem to have a negative effect on the quality of responses. One way of avoiding that might have been to request participants to print out the questionnaire and fill it out on paper before Emailing their responses.
Details of the above study are available in Appendix B.
7.2 Search Tools
Search tool are available for locating resources in different parts of the Internet. Different search tools have to be used for different parts of the Internet, However, since the coming of the World Wide Web, it is possible to perform searches of all these areas through Web gateways.
Various tools available for finding resources on the Internet are discussed in this section.
7.2.1 Archie
Archie is a program that allows searching of anonymous FTP sites all over the world which was developed in 1991 at McGill University Computing Center in Canada. It uses normal FTP commands to get directory listings of all the files on hundreds of anonymous FTP sites all over the world. It then puts all these file listings into a database and provides a simple interface for searching it.
There are Archie servers all over the world and it is usually a good idea to use one that is close by. Responses to Archie searches can take a long time and the situation can be worsened if the Archie server is far away.
Archie servers can be accessed through Telnet, Email, Gopher, World Wide Web and through special client programs.
World Wide Web interfaces to Archie servers can be accessed at the following URLs:
-
Archie Server at Center Universitaire d'Informatique (Switzerland)
http://cuiwww.unige.ch/archieplexform.html
Archie Server at NASA Lewis Research Center
http://www.lerc.nasa.gov/archieplex/doc/form.html
7.2.2 Veronica
Veronica is a program that allows searching of gopher sites all over the world. Veronica was developed at the University of Nevada. It works much like Archie and tunnels through Gopherspace recording the names of available items on hundreds of Gopher sites all over the world. It then puts all these file listings into a database and provides a simple interface for searching it.
There are only a few Veronica servers and it is usually a good idea to use one that is close by. Most Gopher sites provide a link to a Veronica server.
Veronica servers can also be accessed through the World Wide Web at the following URLs:
-
Veronica server at NYSERNet
gopher://empire.nysernet.org:2347/7
Veronica server at PSINet
gopher://veronica.psi.net:2347/7
Veronica server at University of Koeln (Germany)
gopher://veronica.uni-koeln.de:2347/7
Veronica server at the University of Bergen (Norway)
gopher://veronica.uib.no:2347/7
7.2.3 Subject Indexes
A subject index is a tool that provides a structured and organized hierarchy of categories for browsing for information on the World Wide Web. Under each category and/or sub- category, links to appropriate Web pages are listed. Indexes are organized hierarchically and the hierarchies can be arbitrarily deep.
Web pages are assigned categories either by the Web page author or by subject index administrators. Many subject indexes also have their own keyword searchable indexes.
Some subject indexes sites are large with minimal restrictions as to what will be accepted for inclusion. Others provide significant added value to each link with commentaries and ratings provided by skilled reviewers. Subject-specific guides that function as subject bibliographies to Internet resources are also available authored by subject specialists.
The subject-oriented organization of these various subject indexes, while logical, can make it difficult to second guess topics that are not easily categorized. The lack of a controlled vocabulary, within and between different subject indexes, along with ad hoc additions of new categories, increases the difficulty of browsing subject indexes effectively. In general, browsing subject indexes can be a time-consuming activity. So, many subject indexes also provide search options.
Because subject indexes rely on humans for their overall design and maintenance, they typically provide links to a smaller number of documents than most automated search engines. The results of browsing, or even searching an index to a subject index, are likely to be incomplete. However, they can provide excellent starting points for discovering relevant information. Because of their limited coverage of Internet resources, subject indexes do not always do the job and it is usually advisable to supplement a subject index search with a visit to one or more search engines.
The most well known search engine is probably Yahoo (http://www.yahoo.com/) originally started by two students at Stanford. It is now an independent company and is supported by advertising. The basic Yahoo interface allows browsing by category as well as provides a limited search capability.

Figure 7.2 Yahoo Basic Interface
The basic information categories in Yahoo are
- Arts
- Business and Economy
- Computers and Internet
- Education
- Entertainment
- Government
- Health
- News
- Recreation and Sports
- Reference
- Regional
- Science
- Social Science
- Society and Culture
The Yahoo site also provides an advanced search interface which is shown below.
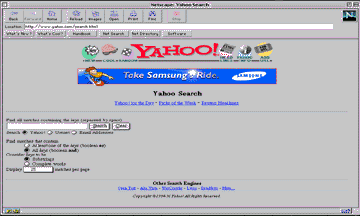
Figure 7.3 Yahoo Advanced Search Interface
Some of the other Subject Indexes are:
-
Galaxy (formerly EINet Galaxy)
http://galaxy.Einet.net/galaxy.html
WWW Virtual Library
http://www.w3.org/hypertext/DataSources/bySubject/overview.html
NetReviews (from Excite)
http://www.excite.com/Subject/
Magellan: McKinley's Internet Directory
http://www.mckinley.com
Whole Internet Catalog (Select) from GNN
http://www-elc.gnn.com/gnn/wic/wics/index.html
7.2.4 Search Engines
Search engines are indexes that are automatically compiled by computer programs, known as robots or spiders, that go out over the Internet to discover and collect information on Internet resources. Users can visit a search engine site and enter keywords to query the index. Web pages and other Internet resources that satisfy the query are identified and listed.
Search engines vary according to the size of the index, the frequency of updating the index, the search options, the speed of returning a result set, the result set presentation, the relevancy of the items included in a result set, and the overall ease of use.
Selecting the right search engine does not necessarily have to be a trial and error process. Connection difficulties, however, often make this choice for the user.
The decision regarding the best search engine to start with depends partly upon a thorough understanding and knowledge of the elements in a document that have been indexed by each engine. For example, Webcrawler indexes every word of a Web page, while the Lycos index is built with only selected words, such as the title, the headings, and the most significant 100 words. These differences contribute to the very different result sets that are returned by different search engines for the same query.
Not all search engines offer the same search options. Some of the engines use 'or' as the default and rely on relevancy ranking algorithms to find and rank relevant documents. Other search engines offer a choice between 'and', 'or', 'adjacent', 'near', and 'not' options. Some search engines also offer several levels of sophistication of search options to cater to different classes of users.
Precision is a major problem. The more sophisticated engines demonstrate better precision. Different search engines are better for some searches than others. Precision can usually be improved by including more terms in the query. But too many terms can also backfire, so you have to be prepared to be persistent and creative.
The sophistication of search options is not the only factor to be considered in determining which engine to use. The size of the index is also a factor. For example, Lycos offers relatively simple search options, but because it indexes the largest number of Internet resources, it is often successful where others fail.
Each search engine varies significantly in the way the result sets are ranked and presented, and this can impact the success of a search. Scanning down a result set before activating any of the links is a recommended strategy. The highest ranked documents in the list are not necessarily those that will provide the desired information. Often the best link is further down the ranked list.
The amount of information provided with each link contributes to the ability to assess the individual links. Webcrawler, at one end of the spectrum, presents a ranked list of links with no additional information. At the other extreme, Lycos generates a lengthy computer-composed abstract for each link which is useful for selecting potentially useful links. OpenText is an example of a search engine that goes even further and suggests links to related sites.
Lycos (http://www/lycos.com) is probably on of the largest search engines. It also offers a classified subject index.
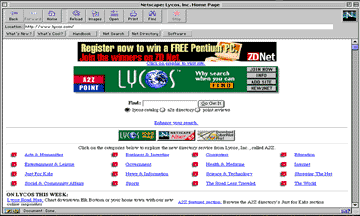
Figure 7.4 Lycos Basic Search Interface
Besides the basic search interface shown above, it also has an advanced search page which allows more controlled searching.
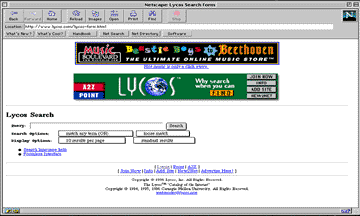
Figure 7.5 Lycos Advanced Search Interface
Some of the other Search Engines are:
-
Excite
http://www.excite.com/
Infoseek
http://www.infoseek.com/
Inktomi
http://inktomi.berkeley.edu
Open Text
http://www.opentext.com/
World Wide Web Worm
http://wwww.cs.colorado.edu/wwww
Webcrawler
http://webcrawler.com/
7.2.5 Case: Locating Design Resources on the Internet
Some of the problems with using search engines are:
- Inconsistent search responses from different search engines
- Large number of hits, many of which may be irrelevant.
This is substantiated by the experiences the author had with a study completed in mid-1995 to identify Design related resources on the Internet.
The primary objective of the research was to assess the current availability of resources or information relevant to Design on the Internet.
The methodology followed for the research was based on identifying search mechanisms for various parts of the Internet, running searches based on keywords (such as design, industrial design, product design, graphic design and visual communication) and documenting the results of the searches.
The results of the searches are briefly listed below.
FTP Sites
Keyword searches using the word "design" were run on Archie servers around the world. The results of the Archie searches are as follows:-
| Germany | 105 hits |
| Finland | 65 hits |
| Japan | 95 hits |
| New Zealand | 75 hits |
| Sweden | 72 hits |
| Taiwan | 70 hits |
| United Kingdom | 65 hits |
| United States | 80 hits |
Gopher Sites
Keyword searches on Veronica yielded the following results:-
| Design | 360 hits |
| Industrial Design | 140 hits |
| Product Design | 55 hits |
| Graphic Design | 130 hits |
| Visual Communication | 40 hits |
World Wide Web
Searches were run using several search engines:-
- ALIWEB (Archie-like Indexing for the Web)
- Jump Station Index
- LYCOS Search Engine
- NIKOS Search Engine
- WebCrawler Search Engine
- World Wide Web Worm
The results of these searches are listed below:-
ALIWEB (Archie-like Indexing for the Web)
| Industrial Design | 67 hits |
| Product Design | 87 hits |
| Graphic Design | 67 hits |
| Visual Communication | 33 hits |
Jump Station Index
| Design | 150 hits |
| Industrial Design | 0 hits |
| Product Design | 5 hits |
| Graphic Design | 7 hits |
| Visual Communication | 0 hits |
LYCOS Search Engine
| Design | 988 hits |
| Industrial Design | 735 hits |
| Product Design | 1000 hits |
| Graphic Design | 1398 hits |
| Visual Communication | 240 hits |
NIKOS Search Engine
| Industrial Design | 5 hits |
| Product Design | 41 hits |
| Graphic Design | 26 hits |
| Visual Communication | 0 hits |
WebCrawler Search Engine
| Industrial Design | 500 hits (of 878) |
| Product Design | 500 hits (of 2049) |
| Graphic Design | 500 hits (of 1596) |
| Visual Communication | 500 hits (of 561) |
World Wide Web Worm
| Design | 501 hits |
| Industrial Design | 3 hits |
| Product Design | 0 hits |
| Graphic Design | 10 hits |
| Visual Communication | 2 hits |
The results of this study clearly demonstrate the problems with search engines which were mentioned earlier:
Inconsistent search responses from different search engines.
Note the extreme differences between Lycos which recorded a total number of hits around 4500 vs. Nikos which managed less than 100 hits for the same set of keywords. Also note the variations between Archie servers located in different countries which registered hits ranging from 65 to 105, a significant degree of variation.
Large number of hits, many of which may be irrelevant.
Lycos registered around 4500 hits for design related keywords checking out which would be a herculean task. Of course, more focused keyword selection would achieve better results, but it does seem clear that there would still be a large number of hits requiring a lot of time to separate the grain from the chaff.
7.3 Serendipity and Brute Browsing
Yet another means of locating information resources on the Internet is serendipity (luck or good fortune, in finding something good accidentally) or brute browsing. While this may not seem to be a very scientific way of locating information, it probably was the only way before the various search engines came into existence. Starting with a particular Web page, the approach is to follow links from page to page, make educated guesses along the way, hoping sooner or later to arrive at the desired piece of information.
This activity can be fun when one has the time to explore, but when one needs to find a specific piece of information quickly, or when one needs to find that same information again, surfing and serendipity soon lose their charm.
However, that is not to say that this approach is not useful at all. Personal experience and the observation that many people maintain personal hotlists of useful sites would tend to suggest that this may form a part of many peoples' resource discovery strategies. Adding weight to this is the proliferation of applications (such as Eastgate Squirrel) whose function is to help people organize and classify their Web bookmarks in a useful manner.
A case in point is the research that the author undertook in mid-1995 to gather information for a proposal for the design of a personal transport vehicle for China. Besides conventional, printed sources of information, extensive information about China was found on the Internet. This included the US Army's Handbook on China, the CIA Factbook on China, the US State Department's Background Notes on China and the US Department of Commerce's Trade Guide to China. Although a lot of this could have been located using the various search engines, in the specific instance being discussed, most of the information was located by sheer chance, while following links that did not seem directly related to the task in hand.
It would be instructive, for example, to follow the route that took this researcher to a site where the US Army Handbook on China is available on-line. This is documented visually in the following pages.
The journey began at (1) UN Home Page .....
Figure 7.6 UN Home Page
(2) ....on to United Nations Information Services .....
Figure 7.7 United Nations Information Sources
(3) .... and then to population information .....
Figure 7.8 Population Information
(4)..... leading to other population servers .....
Figure 7.9 Other Population Servers
(5)..... leading to the Asian Institute of Technology in Bangkok, Thailand .....
Figure 7.10 Asian Institute of Technology, Bangkok, Thailand
(6).... arriving finally at the University of Missouri at St. Louis.
Figure 7.11 University of Missouri at St. Louis
The above journey not only illustrates the fact that it is possible to find useful information serendipitously by brute browsing but also shows that the path to useful data can be long and tortuous.
7.4 Limitations of Information Resources on the Internet
The discussion in the previous sections of this chapter indicates that while there are a lot of information resources available on the Internet, finding them can be a difficult and time consuming task with no guarantee of success. And if one does persevere, the information that one does find suffers from limitations in the following areas:
Copyright
Some documents found on the Internet are in the public domain and have clear indications of rights of use. However, the vast majority of data carries no indication of copyright status.
Reliability
In many instances, the original sources of information are not documented clearly making their reliability questionable.
Currentness
Again, because sources are not always clearly indicated, it is extremely difficult to determine the date and currentness of data.
Usability
Lastly, a lot of information found on the Internet is not in conveniently usable formats, thus limiting the advantages one could gain from the fact that they are electronically encoded. For example, the Army Handbook on China mentioned earlier in this chapter is available in the form of more than 100 separate text documents.