FIND SELECT MODIFIND | ||
A comparative study of three selection algorithms, and their implementations in the Rexx language, for finding Kth smallest of N elements: Hoare's FIND, my modification of FIND (MODIFIND) and Floyd's and Rivest's SELECT. The selection problem can be stated as follows (C. A. R. Hoare in [1]): given an array A of N distinct elements and an integer K, 1 <= K <= N, determine the Kth smallest element of A and rearrange the array in such a way that this element is placed in A[K] and all elements with subscripts lower than K have fewer values and all elements with subscripts greater than K have greater values. Thus on completion of the program, the following relationship will hold:
The usefulness of a solution of this problem arises from its application to the problem of finding the median or other quantiles or finding the minimum or the maximum or second-largest elements ... Straightforward solution would be to sort the whole array. But if the array is large, the time taken to sort it will also be large. I'll introduce a faster algorithm due to C. A. R. Hoare. He called his program FIND (I'll refer to the implementation in this article as H) and it selects the Kth smallest element in just O(N) average time. The H algorithmHoare's algorithm is based on the following corollary of the obvious definition:
We begin with a conjecture: A[K] is Kth smallest. The algorithm of the proof or rejection this conjecture is: The array is divided by scanning from the left (for indexes I = 1, 2, ...) to find an element A[I] >= A[K], scanning from the right (for indexes J = N, N - 1, ... ) to find an element A[J] <= A[K], exchanging them, and continuing the process until the pointers I and J cross. This procedure gives three cases:
Q. E. D. Kth smallest element is in its final place and the program finished. Example:
A[1] ... A[J] are less than N - K + 1 other elements, exactly they are less than N - I + 1 >= N - K + 1 elements. I. e. any one can't be Kth smallest, so we'll find (K - I + 1)th smallest element in the subarray A[I] ... A[N]. Example:
A[I] ... A[N] are greater than K other elements, exactly they are greater than J >= K elements. I. e. any one can't be Kth smallest, so we'll find Kth smallest element in the subarray A[1] ... A[J]. Example: The following program H ilustrates this algorithm. It is the translation Niklaus Wirth's program from [6] to the Rexx language.
The analysis of the H algorithmLet us determine the number of comparisons, as A.I < X is, and swaps W = A.I; A.I = A.J; A.J = W that H makes. Let C(N, K) be the number of comparisons made by H when applied to finding Kth smallest of N elements, and let S(N, K) be the number of swaps of items. In worst case:
In [3] I showed examples of arrays for worst cases (Kth position is red coloured):
In average case (D. E. Knuth in [2]):
where
This yields as special cases:
I proved:
Corollary:
The Z algorithmWe consider the array 1, 10, 2, 3, 4, 5, 6, 7, 8, 9, and K= 2. The array is split into two parts A[1], ..., A[9] and A[10]: 1, 9, 2, 3, 4, 5, 6, 7, 8 and 10 by the help of one swap and 12 comparisons. But when I find that 10 is greater than two elements (1 and 9) then I know: it can't be second smallest element. I can reach the same result (1, 9, 2, 3, 4, 5, 6, 7, 8, 10) by the help of one swap and three comparisons and I'll search second smallest element in the subarray A[1], ..., A[9]. This modification of the H algorithm describes the program Z. It is the translation to the Rexx language from my article [3], I called it MODIFIND for Algorithms, Data Structures, and Problems Terms and Definitions of the CRC Dictionary of Computer Science, Engineering and Technology:
The analysis of the Z algorithmIn worst case
In worst case the number of comparison for the algorithm H doesn't depend on K. But for the algorithm Z the number of comparison depends on K. The following graph shows the time of execution H and Z in worst case. 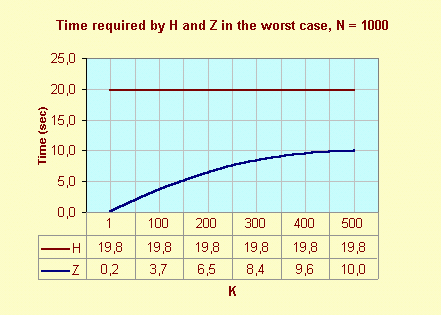
In average caseIn [3] I state only values of C(N, 1), C(N, N) and S(N, K):
This yields as special cases:
The FR algorithmIn their article Expected Time Bounds for Selection[4] R. W. Floyd and R. Rivest presented a new selection algorithm SELECT which is shown to be very efficient on the average, both theoretically and practically. The number of comparisons used to select the Kth smallest of N numbers is N + min(K, N - K) + o(N). I express SELECT in the Rexx language as the FR program.
Floyd and Rivest in [5] write: The arbitrary constants 600, 0.5, 0.5 appearing in the algorithm minimize execution time on the particular machine used.I experimentally found that constants 600, 0.5, 0.5 are the good choice. For classic Rexx there is a problem with functions LN, EXP and SQRT (they aren't built-in). But hundreds experiments for N = 10000 shown, that the maximum precisionnumeric digits 6 will be sufficient. Hence I used the following simple algorithms from textbooks:
I experimantally found that for achievement of the lowest average time is the best choice: the constant 3 in statement numeric digits and the constant 5E-3. For the lowest number of comparisons I found more candidates: sometimes 4 and 5E-3 or 5 and 5E-5 or 6 and 6E-6 ... I used 3 and 5E-3 because the FR program was fastest as well as. The results showed that the average number of comparisons for finding the median is proportional to 1.5N. Comparisons of AlgorithmsFor comparisons I used the program as following one (this example is only for timing results and for K >= 500):
As a measuring instrument I used my PC with 6x86MX-PR233 processor and 32MB RAM. The graph Average time required H, Z, FR shows, that Z is faster than FR only for K = 1. I repeated a few times the measuring and always the finding of the median was faster than the finding of the K-th element, for K = 3000 or 4000.  The graph H, Z, FR - comparison count, average case explains previous results. It proves that the Knuth's estimate of the average case for the number of comparison for H holds, too. The Z algorithm is best only for K = 1 otherwise FR is the winner. The theoretical result for FR for the finding of the median holds, i. e. 1.5N comparisons.  The graph H, Z, FR - swap count, average case shows that Z has the least count of swaps. It shows that my estimate for S(N, K) for Z holds as well as. 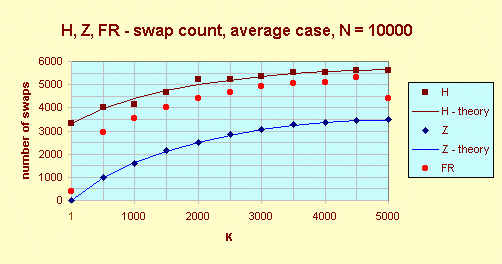 ConclusionAlgorithms Z and FR are always better than H; FR has fewer the number of
comparison than Z; Z has fewer the number of swaps than FR. For additional information see my page About MODIFIND. Richard Harter's comment in comp.programming It is interesting. One of the attractive things about the Z algorithm is that
it is simple and easy to code. This is no small thing; quite often one is
trading off coding time versus performance time. In any case it is nice to
know where to find the algorithms on line. What is the difference between Mechanical Engineers and Civil Engineers? Literature |
|
|
|
|
|
|
|
|
|
 |
last modified 26th April 2002
Copyright © 1998-2002 Vladimir Zabrodsky
Czech Republic