Studie porovnává tři algoritmy nalezení K-tého nejmenšího z N prvků: Hoarův FIND [1], moji modifikaci programu FIND [3] (nazval jsem jej MODIFIND v Algorithms, Data Structures, and Problems Terms and Definitions of the CRC Dictionary of Computer Science, Engineering and Technology, version February 4, 1999) a Floydův a Rivestův SELECT [4], [5]. Pro měření doby výpočtu, počtu porovnání a výměn prvků jsem využil implementace algoritmů v jazyce Rexx (Quercus Systems' Personal REXX for Windows) na počítači PC s procesorem 6x86MX-PR233, 32MB RAM v prostředí Windows 98.
Problém nalezení K-tého nejmenšího z N prvků definoval C. A. R. Hoare v [1] takto: Je dáno pole A obsahující N navzájem různých prvků a celé čílo K, 1 <= K <= N, má se určit K-tý nejmenší prvek A a pole se má přerovnat tak, aby prvek A[K] výsledného pole byl K-tým nejmenším prvkem a všechny prvky s indexem menším než K měly menší hodnotu a všechny prvky s indexem větším než K měly větší hodnotu. Musí tedy platit:
|
Řešení tohoto problému můžeme využít v praxi pro nalezení mediánu nebo jiného kvantilu stejně jako pro určení nejmenšího, největšího nebo druhého největšího atd. prvku. Přímočaré řešení - pole nejdříve vytřídit - by mohlo být časově náročné při velkém počtu prvků. Rychlejší algoritmus publikoval poprvé C. A. R. Hoare a nazval jej FIND. V této práci jej budu označovat jako H.
Algoritmus H
Hoarův algoritmus je založen na zřejmém důsledku známé definice:
| DEFINICE |
| DŮSLEDEK |
Při výpočtu vyjdeme z předpokladu, že
A[K] je K-tým nejmenším prvkem a pokusíme se to dokázat následujícím postupem:
Pole se prohlíží zleva (tj. zkoumají se prvky s indexy I = 1, 2, ...) až se nalezne
prvek A[I] >= A[K], pak se prohlíží pole zprava (tj. zkoumají se prvky s indexy J = N, N - 1, ... ) až se nalezne prvek
A[J] <= A[K], oba prvky se vymění, v procesu zkoumání a výměn se pokračuje tak dlouho, dokud se ukazatelé I a J nestřetnou. Pak může nastat jeden ze tří možných případů:
| PŘÍPAD 1 (J < K < I) |
Tvrzení je dokázáno. K-tý nejmenší prvek je na správném místě a program končí. Příklad:
| PŘÍPAD 2 (J < I <= K) |
Prvky A[1] ... A[J] jsou menší než N - K + 1 jiných prvků, přesně řečeno jsou menší než N - I + 1 >= N - K + 1 prvků, žádný z nich tedy nemůže být K-tým nejmenším prvkem. Pokračovat ve výpočtu proto budeme hledáním prvku, který je (K - I + 1)-ním nejmenším prvkem v poli A[I] ... A[N]. Příklad:
| PŘÍPAD 3 (K <= J < I) |
Prvky A[I] ... A[N] jsou větší než K jiných prvků, přesně řečeno jsou větší než J >= K prvků. Žádný z nich tedy nemůže být K-tým nejmenším prvkem. Pokračovat budeme v řešení úlohy redukovaného rozsahu: Nalézt K-tý nejmenší prvek pole A[1] ... A[J]. Příklad:
Popsaný algoritmus ilustruje program H, který je mým překladem programu Niklause Wirtha z [6] do jazyka Rexx.
|
Analýza algoritmu H
Složitost algoritmu budeme posuzovat z počtu porovnání, jako je A.I < X a z počtu výměn W = A.I; A.I = A.J; A.J = W. Nechť C(N, K) označuje počet porovnání a S(N, K) počet výměn nutných při provádění programu H k nalezení K-tého nejmenšího z N prvků.
V nejhorším případě je:
|
V [3] ukazuji příklady polí, které vedou k nejhoršímu případu (prvek v K-té pozici je označen červeně):
|
V průměrném případě platí podle D. E. Knutha [2]:
|
kde
|
V speciálních případech tedy platí:
|
Já jsem odvodil vzorec pro určení průměrného počtu výměn:
|
Důsledek:
|
Algoritmus Z
Uvažme pole 1, 10, 2, 3, 4, 5, 6, 7, 8, 9, a K = 2. Pole se rozdělí výše uvedeným postupem na dvě části A[1], ..., A[9] a A[10]: 1, 9, 2, 3, 4, 5, 6, 7, 8, 10 pomocí jedné výměny a 12-ti porovnání. Zjistím-li však, že 10 je větší než dva prvky (1 a 9), pak už přece vím, že nemůže být druhým nejmenším prvkem, a další porovnání jsou tedy zbytečná. Stejného výsledku (1, 9, 2, 3, 4, 5, 6, 7, 8, 10) dosáhnu jen s pomocí jedné výměny a třech porovnání. A pak mohu hned přejít na řešení redukované úlohy najít v poli A[1], ..., A[9] druhý nejmenší prvek. Modifikaci algoritmu H, pracující tímto způsobem, popisuje následující program Z. Je překladem mého programu z [3] do jazyka Rexx.
|
Analýza algoritmu Z
V nejhorším případě:
|
U algoritmu Z maximální počet porovnání závisí na K. Následující graf ukazuje naměřenou dobu výpočtu H a Z v nejhorším případě.

V [3] jsem uvedl jen odhady pro průměrnou hodnotu C(N, 1), C(N, N) a S(N, K):
|
|
V speciálním případě tedy:
|
Algoritmus FR
Ve svém článku Expected Time Bounds for Selection [4] R. W. Floyd a R. L. Rivest popsali nový, efektivní algoritmus. Počet porovnání je v průměrném případě roven N + min(K, N - K) + o(N). Následující program FR je mým překladem původního programu z [5] do jazyka Rexx.
|
Floyd a Rivest v [5] píší: Konstanty 600, 0.5, 0.5, vykytující se v popisu algoritmu, minimizovaly dobu výpočtu na používaném počítači. Ověřil jsem experimentálně, že hodnoty 600, 0.5, 0.5 jsou dobrým výběrem. U klasického Rexxu je tu problém s funkcemi LN, EXP a SQRT, protože nejsou součástí jazyka. Stovky experimentů ukázaly, že pro N = 10000 vystačíme s přesností výpočtu určenou příkazem numeric digits 6. Proto jsem použil algoritmy známé z učebnic:
|
|
|
Experimentálně jsem zjistil, že nejrychleji výpočet proběhne, vydáme-li ve výše uvedených procedurách příkaz numeric digits 3 a srovnáváme-li hodnotu právě vypočteného členu s hodnotou 5E-3. Pro určení co nejmenšího počtu porovnání jsem ale jednoznačně nejlepší hodnoty těchto konstant nenašel. Někdy byla nejúspěšnější volba konstant 3 a 5E-3, jindy 4 a 5E-3, jindy zase 5 a 5E-5 nebo 6 a 6E-6. Nakonec jsem použill hodnoty 3 a 3E-5, s kterými byl výpočet zároveň nejrychlejší. Výsledek průměrného počtu porovnání při nalezení mediánu, 1.5N v dále uvedeném grafu, ukazuje, že program FR s těmito hodnotami pracuje podle očekávání.
Porovnání algoritmů
Pro porovnání jsem použil program COMPARISON. Dále uvedený zjednodušený příklad tohoto programu měří jen dobu výpočtu pro hodnoty K >= 500.
|
První graf ukazuje, že Z je rychlejší než FR jen pro K = 1. Mnohokrát jsem opakoval měření, abych si potvrdil, že algoritmus FR vyžaduje méně operací porovnání pro nalezení mediánu, a spotřebuje proto i méně času, než pro nalezení prvku, který je v pořadí podle velikosti 3000. nebo 4000.

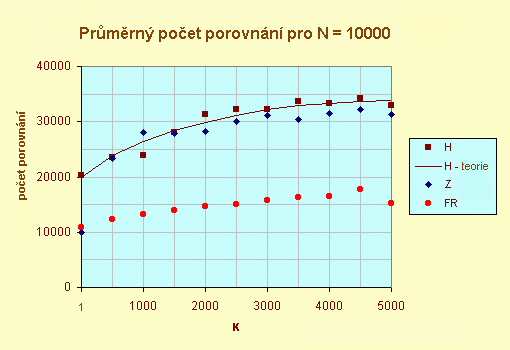
Druhý graf porovnává počet porovnání (povšimněte si anomálie týkající se nižšího počtu operací porovnání u mediánu). Graf zároveň ukazuje, že Knuthův odhad pro průměrný počet operací porovnání u algoritmu H je správný. Algoritmus Z je nejlepší pro K = 1 a je o něco lepší než H; ale jasným vítězem v této kategorii je FR. Graf konečně dokazuje, že implementace v jazyce Rexx SELECTu neublížila - pro výpočet mediánu je opravdu v průměru zapotřebí jen 1.5N porovnání.
Poslední graf ukazuje, že Z potřebuje v průměru nejméně výměn. Navíc ukazuje, že můj odhad hodnoty S(N,K) pro Z je přesný.

Závěr
Algoritmy Z a FR jsou vždy lepší než H; FR provede v průměru méně operací porovnání než Z; Z provede v průměru méně výměn než FR. Další informace uvádím v článku O algoritmu MODIFIND.
Komentář Richarda Hartera v comp.programming To je zajímavé. K přitažlivým vlastnostem algoritmu Z patří jeho jednoduchost. To není maličkost. Při výběru algoritmu často srovnáváme jeho časovou složitost s dobou strávenou na jeho kódování a ladění. V každém případě je hezké mít tyto algoritmy k dispozici on-line.
Literatura
Richard Harter, cri@tiac.net, The Concord Research Institute
http://www.tiac.net/users/cri
Jaký je rozdíl mezi civilním a vojenským inženýrem?
Vojenský staví zbraně, civilní cíle.
1. C. A. R. HOARE: Proof of a Program: FIND. CACM, Vol 14,
No. 1, January 1971, pp. 39-45.
2. D. E. KNUTH: The Art of Computer Programming. Sorting and Searching.
Addison-Wesley, Reading, Mass., 1973.
3. V. ZÁBRODSKÝ: Variace na klasické téma.
Elektronika, No. 6, 1992, pp. 33-34.
4. R. W. FLOYD, R. L. RIVEST:
Algorithm 489 The Algorithm SELECT - for Finding the ith
Smallest of n Elements [M1]. CACM, March 1975, Vol. 18, No. 3, p. 173.
5. R. W. FLOYD, R. L. RIVEST:
Expected Time Bounds for Selection. CACM, March 1975, Vol. 18, No. 3, pp. 165-172.
6. N. WIRTH: Algorithms and data structures. New Jersey 07632, Prentice Hall, Inc.,
Engelwood Cliffs, 1986.