
A* algorithm tutorial
Please use the google project to report issues
A* on Google CodeNews
THIS SITE HAS MOVED TO www.heyes-jones.com/astar.htmlPLEASE UPDATE ANY BOOKMARKS, YOU WILL BE REDIRECTED SHORTLY This is due to Geocities imminent cancellation of their free hosting services.
Recent blog posts
Who uses this A* codeBug fixes
Avoiding ten common video game AI mistakes
Introduction
This document contains a description of the AI algorithm known as A*. The downloads section also has full source code for an easy to use extendable implementation of the algorithm, and two example problems.Previously I felt that it would be wrong of me to provide source code, because I wanted to focus on teaching the reader how to implement the algorithm rather than just supplying a ready made package. I have now changed my mind, as I get many emails from people struggling to get something working. The example code is written in Standard C++ and uses STL, and does not do anything machine or operating system specific, so hopefully it will be quite useful to a wide audience.
State space search
A* is a type of search algorithm. Some problems can be solved by representing the world in the initial state, and then for each action we can perform on the world we generate states for what the world would be like if we did so. If you do this until the world is in the state that we specified as a solution, then the route from the start to this goal state is the solution to your problem.In this tutorial I will look at the use of state space search to find the shortest path between two points (pathfinding), and also to solve a simple sliding tile puzzle (the 8-puzzle). Let's look at some of the terms used in Artificial Intelligence when describing this state space search.
Some terminology
A node is a state that the problem's world can be in. In pathfinding a node would be just a 2d coordinate of where we are at the present time. In the 8-puzzle it is the positions of all the tiles.
Next all the nodes are arranged in a graph where links between nodes represent valid steps in solving the problem. These links are known as edges. In the 8-puzzle diagram the edges are shown as blue lines. See figure 1 below.
State space search, then, is solving a problem by beginning with the start state, and then for each node we expand all the nodes beneath it in the graph by applying all the possible moves that can be made at each point.
Heuristics and Algorithms
At this point we introduce an important concept, the heuristic. This is like an algorithm, but with a key difference. An algorithm is a set of steps which you can follow to solve a problem, which always works for valid input. For example you could probably write an algorithm yourself for multiplying two numbers together on paper. A heuristic is not guaranteed to work but is useful in that it may solve a problem for which there is no algorithm.
We need a heuristic to help us cut down on this huge search problem. What we need is to use our heuristic at each node to make an estimate of how far we are from the goal. In pathfinding we know exactly how far we are, because we know how far we can move each step, and we can calculate the exact distance to the goal.
But the 8-puzzle is more difficult. There is no known algorithm for calculating from a given position how many moves it will take to get to the goal state. So various heuristics have been devised. The best one that I know of is known as the Nilsson score which leads fairly directly to the goal most of the time, as we shall see.
Cost
When looking at each node in the graph, we now have an idea of a heuristic, which can estimate how close the state is to the goal. Another important consideration is the cost of getting to where we are. In the case of pathfinding we often assign a movement cost to each square. The cost is the same then the cost of each square is one. If we wanted to differentiate between terrain types we may give higher costs to grass and mud than to newly made road. When looking at a node we want to add up the cost of what it took to get here, and this is simply the sum of the cost of this node and all those that are above it in the graph.
8 Puzzle
Let's look at the 8 puzzle in more detail. This is a simple sliding tile puzzle on a 3*3 grid where one tile is missing and you can move the other tiles into the gap until you get the puzzle into the goal position. See figure 1.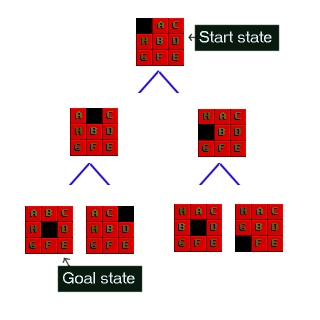
Figure 1 : The 8-Puzzle state space for a very simple example
There are 362,880 different states that the puzzle can be in, and to find a solution the search has to find a route through them. From most positions of the search the number of edges (that's the blue lines) is two. That means that the number of nodes you have in each level of the search is 2^d where d is the depth. If the number of steps to solve a particular state is 18, then that�s 262,144 nodes just at that level.
The 8 puzzle game state is as simple as representing a list of the 9 squares and what's in them. Here are two states for example; the last one is the GOAL state, at which point we've found the solution. The first is a jumbled up example that you may start from.
Start state SPACE, A, C, H, B, D, G, F, E Goal state A, B, C, H, SPACE, D, G, F, E The rules that you can apply to the puzzle are also simple. If there is a blank tile above, below, to the left or to the right of a given tile, then you can move that tile into the space. To solve the puzzle you need to find the path from the start state, through the graph down to the goal state.
There is example code to to solve the 8-puzzle on the google code page.
Pathfinding
In a video game, or some other pathfinding scenario, you want to search a state space and find out how to get from somewhere you are to somewhere you want to be, without bumping into walls or going too far. For reasons we will see later, the A* algorithm will not only find a path, if there is one, but it will find the shortest path. A state in pathfinding is simply a position in the world. In the example of a maze game like Pacman you can represent where everything is using a simple 2d grid. The start state for a ghost say, would be the 2d coordinate of where the ghost is at the start of the search. The goal state would be where pacman is so we can go and eat him. There is also example code to do pathfinding on the google code page.
Figure 2 : The first three steps of a pathfinding state space
Implementing A*
We are now ready to look at the operation of the A* algorithm. What we need to do is start with the goal state and then generate the graph downwards from there. Let's take the 8-puzzle in figure 1. We ask how many moves can we make from the start state? The answer is 2, there are two directions we can move the blank tile, and so our graph expands.If we were just to continue blindly generating successors to each node, we could potentially fill the computer's memory before we found the goal node. Obviously we need to remember the best nodes and search those first. We also need to remember the nodes that we have expanded already, so that we don't expand the same state repeatedly.
Let's start with the OPEN list. This is where we will remember which nodes we haven't yet expanded. When the algorithm begins the start state is placed on the open list, it is the only state we know about and we have not expanded it. So we will expand the nodes from the start and put those on the OPEN list too. Now we are done with the start node and we will put that on the CLOSED list. The CLOSED list is a list of nodes that we have expanded.
f = g + h
Using the OPEN and CLOSED list lets us be more selective about what we look at next in the search. We want to look at the best nodes first. We will give each node a score on how good we think it is. This score should be thought of as the cost of getting from the node to the goal plus the cost of getting to where we are. Traditionally this has been represented by the letters f, g and h. 'g' is the sum of all the costs it took to get here, 'h' is our heuristic function, the estimate of what it will take to get to the goal. 'f' is the sum of these two. We will store each of these in our nodes.
Using the f, g and h values the A* algorithm will be directed, subject to conditions we will look at further on, towards the goal and will find it in the shortest route possible.
So far we have looked at the components of the A*, let's see how they all fit together to make the algorithm :
Pseudocode
Hopefully the ideas we looked at in the preceding paragraphs will now click into place as we look at the A* algorithm pseudocode. You may find it helpful to print this out or leave the window open while we discuss it.
To help make the operation of the algorithm clear we will look again at the 8-puzzle problem in figure 1 above. Figure 3 below shows the f,g and h scores for each of the tiles.

Figure 3 : 8-Puzzle state space showing f,g,h scores
First of all look at the g score for each node. This is the cost of what it took to get from the start to that node. So in the picture the center number is g. As you can see it increases by one at each level. In some problems the cost may vary for different state changes. For example in pathfinding there is sometimes a type of terrain that costs more than other types.
Next look at the last number in each triple. This is h, the heuristic score. As I mentioned above I am using a heuristic known as Nilsson's Sequence, which converges quickly to a correct solution in many cases. Here is how you calculate this score for a given 8-puzzle state :
Nilsson's sequence score
A tile in the center scores 1 (since it should be empty)
For each tile not in the center, if the tile clockwise to it is not the one that should be clockwise to it then score 2. Multiply this sequence by three and finally add the total distance you need to move each tile back to its correct position. Reading the source code should make this clearer.
Looking at the picture you should satisfy yourself that the h scores are correct according to this algorithm.
Finally look at the digit on the left, the f score. This is the sum of g and h, and by tracking the lowest f down through the state space you are doing what the A* algorithm would be doing during its search.
Let me now look at the example source code provided with the tutorial, for although the algorithm at this stage may be clear in your mind the implementation is a little complicated. The language of choice for this kind of algorithm is really Common Lisp or Prolog, and most Universities use these when teaching. This effectively lets students focus on the algorithm rather than the implementation details such as memory and data stuctures. For our purposes however, I will refer to my example source code. This is in C++ and uses standard library and STL data structures.
C++ implementation details
If you intend on compiling and running the example code then you can get it on the google code page. I have not put any project, workspace or makefiles in the archive, but compilation and linking should be straight forward; the programs run from a command line. As we will see the A* algorithm is in a header file, since it is implemented as a template class, so to compile you need only compile on of the example files 8puzzle.cpp or findpath.cpp.
There are comments throughout the source, and I hope it is clear and readable. What follows then is a very brief summary for how it works, and the basic design ideas.
The main class is called AStarSearch, and is a template class. I chose to use templates because this enables the user to specialise the AStarSearch class to their user state in an efficient way. Originally I used inheritence from a virtual base class, but that lead to the use of type casts in many places to convert from the base Node to the user's node. Also templates are resolved at compile time rather than runtime and this makes them more efficient and require less memory.
You pass in a type which represents the state part of the problem. That type must contain the data you need to represent each state, and also several member functions which get called during the search. These are described below :
float GoalDistanceEstimate( PuzzleState &nodeGoal );
Return the estimated cost to goal from this node
bool IsGoal( PuzzleState &nodeGoal );
Return true if this node is the goal
void GetSuccessors( AStarSearch
For each successor to this state call the AStarSearch's AddSuccessor call to add each one to the current search
float GetCost( PuzzleState *successor );
Return the cost moving from this state to the state of successor
bool IsSameState( PuzzleState &rhs );
Return true if the provided state is the same as this state
The idea is that you should easily be able to implement different problems. All you need do is create a class to represent a state in your problem, and then fill out the functions above.
Once you have done that you create a search class instance like this :
AStarSearch
Then the create the start and goal states and pass them to the algorithm to initialize the search :
astarsearch.SetStartAndGoalStates( nodeStart, nodeEnd );
Each step (a step is getting the best node and expanding it's successors) you call :
SearchState = astarsearch.SearchStep();
Which returns a status which let's you know whether the search succeeded, failed, or is still going.
Once your search succedes you need to be able to display it to the user, or use it in your program. To facilitate this I have added functions to allow movement through the solution.
UserState *GetSolutionStart();
UserState *GetSolutionNext()
UserState *GetSolutionEnd();
UserState *GetSolutionPrev()
You use these to move an internal iterator through the solution. The most typical use would be to GetSolutionStart (the start state) and the iterate through each node using GetSolutionNext. For debugging purposes or some problems you may need to iterate through the solution backwards, and the second two functions allow that.
Debugging and Educational functions
Let's say you decide to display the OPEN and CLOSED lists at each step of the solution. This is a common debug feature whilst getting the algorithm working. Further, for the student it is often easier to see what is going on this way. Using the following calls you can display the lists during the search process...
UserState *GetOpenListStart( float &f, float &g, float &h );
UserState *GetOpenListNext( float &f, float &g, float &h );
UserState *GetClosedListStart( float &f, float &g, float &h );
UserState *GetClosedListNext( float &f, float &g, float &h );
As you see these calls take references to float values for f,g and h so if your debugging or learning needs involve looking at these then you can pass floats in to store the results. If you don't care these are optional arguments.
Examples of how you use these features are present in both the findpath.cpp and 8puzzle.cpp example files.
I hope that at this point you will understand the key concepts you need, and by reading and experimenting with the example code (stepping through it with a debugger is very instructive) you hopefully will fully grasp the A* Algorithm. To complete this introduction I will briefly cover Admissibility and Optimization issues.
Admissibility
Any graph search algorithm is said to be admissible if it always returns an optimal soution, that is the one with the lowest cost, if a solution exists at all.However, A* is only admissible if the heuristic you use h' never over-estimates the distance to the goal. In other words if you knew a heuristic h which always gave the exact distance to goal then to be admissible h' must be less than or equal to h.
For this reason when choosing a heuristic you should always try to ensure that it does not over-estimate the distance the goal. In practice this may be impossible. Look at the 8-puzzle for example; in our heuristic above it is possible that we may get an estimated cost to goal that is higher than is really neccessary. But it does help you to be aware of this theory. If you set the heuristic to return zero, you will never over-estimate the distance to goal, but what you will get is a simple search of every node generated at each step (breadth-first search).
One final note about admissibility; there is a corollary to this theory called the Graceful Decay of Admissibility which states that if your heuristic rarely over-estimates the real distance to goal by more than a certain value (lets call it E) then the algorithm will rarely find a solution which costs more than E over the cost of the optimal solution.
Optimization
A good source of optimizations for A* can be found in Steve Rabin's chapters in Game Gems, which is on the books page. The forthcoming book AI Wisdom by the same publisher is going to have several chapters on optimization of A*. These of course focus on pathfinding, which is the ubiquitous use of A* in games.Optimizing pathfinding is a whole subject in itself and I only want to target the A* algorithm for general use, but there are some obvious optimizations you will want to make for most problems. After testing my example code with VTune I found the two main bottlenecks were searching the OPEN and CLOSED lists for a new node, and managing new nodes. A simple but very effective optimization was to write a simpler memory allocator than the C++ std new uses. I have provided the code for this class and you can enable it in stlastar.h. I may write a tutorial on it in the future if there is sufficient interest.
Since you always want to get the node with the lowest 'f' score off the OPEN list each search loop you can use a data structure called a 'priority queue'. This enables to you to organise your data in a way in which the best (or worst depending on how you set it up) item can always be removed efficiently. Steve Rabin's chapter in the book above shows how to use an STL Vector along with heap operations to get this behaviour. My source code uses this technique
If you are interested in priority queues follow the link above to my old A* tutorial as I implemented one from scratch in C, and the source code has been used in public projects such as FreeCell Solver
Another optimization is that instead of searching the lists you should use a hash table. This will prevent you having to do a linear search. A third optimization is that you never need to backtrack in a graph search. If you look at pathfinding for example you will never be nearer to the goal if you step back to where you came from. So when you write your code to generate the successor's of a node, you can check the generated ones and eliminate any states that are the same as the parent. Although this makes no difference to the operation of the algorithm it does make backtracking quicker.
The key to optimization is not to do it until you have your code working and you know that your problem is correctly represented. Only then can you start to optimize the data structures to work better for your own problem. Using VTune or True Time, or whatever profiler you have available is the next step. In some problems checking to see if something is the goal or not may be costly, whilst in others generating the successor nodes at each step may be a significant bottleneck. Profiling takes the guesswork out of finding where the bottleneck is, so that you can target the key problems in your application.
Report bugs and get the latest code from google project
a-star-algorithm-implementationFor more information
http://www.gamasutra.com/features/19990212/sm_01.htm
http://www.gameai.com
Other implementations on the web
If this list is out of date or you would like to add an implementation link I be grateful for your email.http://www.codeproject.com/csharp/CSharpPathfind.asp
http://www.riversoftavg.com/downloads.htm
http://www.spritelab.dk/beta/Astar2.html
http://www.ccg.leeds.ac.uk/james/aStar
http://yoda.cis.temple.edu:8080/UGAIWWW/resources/search-resources.html
http://www.gameai.com/javastar.html
http://www.idevgames.com/fileshow.php3?showid=179