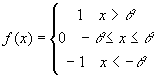
During the early years of neural network research, the perceptron was considered the most successful type of network. The training algorithm used by perceptron networks is based on mathematics, not on biological phenomenon. In spite of this, the algorithm looks surprisingly like the Hebb rule. In fact the only difference between the perceptron network and the Hebb Net, is a slight adjustment of the learning rule and a new activation function. Instead of using a simple bipolar or binary threshold function, the perceptron uses a new function that allows for a boundary region instead of a boundary line between the two output categories. The new activation function is the following:
This activation function allows an output node in a perceptron to have three responses as opposed to the two we were limited to in a Hebb Net. If we think of one to mean yes and negative one to mean no, zero would then mean I don’t know. If a trained perceptron network is presented with data that doesn’t seem to fit into the categories it was trained for, the network will probably output 0, instead of classifying the input into a category it doesn’t belong to.
The training rule for a perceptron, as was
stated earlier, is very similar to the mathematical
interpretation of the Hebb Rule. The perceptron training rule
simply adds a learning rate constant. The new rule looks like
this: ![]() , where t
is the target output value, and a is the learning rate
constant. The purpose of the learning rate constant is to allow
the weights to take on a greater range of values. This allows the
network to have more flexibility during training. However because
of the greater changes, the weights converge upon the ideal set
of weights more slowly. When using the perceptron training rule,
instead of always updating the weights, you only update the
weights if the output values calculated by the network are
different from the desired output values. This prevents the
network from unlearning information learned by previous training
patterns. There is one last difference in the perceptron training
process. Instead of going through each training pattern once
during the training process, you must repeat the process with the
same set of training patterns until no weight changes occur. If
no weight changes occur for an entire epoch, one iteration of
training with all training patterns, then the network is
completely trained and training stops.
, where t
is the target output value, and a is the learning rate
constant. The purpose of the learning rate constant is to allow
the weights to take on a greater range of values. This allows the
network to have more flexibility during training. However because
of the greater changes, the weights converge upon the ideal set
of weights more slowly. When using the perceptron training rule,
instead of always updating the weights, you only update the
weights if the output values calculated by the network are
different from the desired output values. This prevents the
network from unlearning information learned by previous training
patterns. There is one last difference in the perceptron training
process. Instead of going through each training pattern once
during the training process, you must repeat the process with the
same set of training patterns until no weight changes occur. If
no weight changes occur for an entire epoch, one iteration of
training with all training patterns, then the network is
completely trained and training stops.
Since this training algorithm isn’t based on biology, why does it work? The answer to this question is unfortunately very complicated. In fact, the proof that shows that it will work is more complex than the proofs for some of the more powerful training algorithms. Reading the proof gives very little insight into why the neural network works. It is just a lot of vector and matrix mathematics combined with some amazing deductive logic. Because of its complexity, the proof for this training process is going to be omitted. However just remember that there is a theorem, the Perceptron Learning Rule Convergence Theorem, that proves this training algorithm will work if a set of weights that solves the given problem exists. Just for reference, a statement of the theorem is as follows:
If there is a weight vector w* such that f(x(p)w*)=t(p) for all p, then for any starting vector w, the perceptron learning rule will converge to a weight vector (not necessarily unique and not necessarily w*) that gives the correct response for all training patterns, and it will do so in a finite number of steps. (Fausett 77)
![]()
Home Page ![]() Introduction
Introduction ![]() Biological Neural
Networks
Biological Neural
Networks ![]() McCulloch-Pitts Neuron
McCulloch-Pitts Neuron
Perceptron ![]() Adaline
Adaline ![]() Back Propagation
network
Back Propagation
network
References ![]() Research Paper
Research Paper ![]() Glossary
Glossary
![]() Beware: This
page is always under construction
Beware: This
page is always under construction
![]() Geocities
Geocities
![]() Geocities
Research Triangle
Geocities
Research Triangle